

PDF/A and external references
ArticleNovember 13, 2025

ArticleNovember 13, 2025

About Peter Wyatt, PDF Association
BUSINESS NOTE
Comprehensive archival policy frameworks often need to provide guidance on identifying which categories of URLs (or URIs) are of interest in PDF/A files. Understanding how PDF hyperlinks work and where URLs can be specified in PDF (and thus PDF/A) is crucial in auditing documents for external references.
After my recent iPRES 2025 tutorial titled “A forensic spotlight on PDF/A”, I was asked by several attendees regarding “external references” in PDF/A (ISO 19005) files. After some discussion, I realized that some archivists and digital librarians aren’t entirely sure about the exact meaning and significance of terms such as “external dependencies” and “external references”. I believe the confusion arises from NOTE 1 in the Stream objects subclause (subclause 6.1.7.1 of PDF/A-2 (ISO 19005-2:2011) and PDF/A-3 (ISO 19005-3:2012), and subclause 6.1.6.1 of PDF/A-4 (ISO 19005-4:2020)), which states:
NOTE 1 ... The explicit prohibition of these keys has the implicit effect of disallowing external content that can create external dependencies and complicate preservation efforts.
In many archival and digital library preservation scenarios, comprehensive preservation efforts often involve reviewing all content references in the document, including URLs in bibliographic references, footnotes, and annotations. Although such reviews can be crucial to the preservationist’s mission, these types of “external references” are not what these subclauses in PDF/A describe.
This article aims to help archivists and digital librarians develop appropriate policies and procedures, and assist in evaluating technologies that can extract a list of all “external references”. It also explains how to audit any PDF (and thus also PDF/A) document for various external references, such as URLs.
PDF/A is a file format
PDF/A is primarily a file format specification. As such, it does not impose restrictions on the content that can be preserved in PDF/A files, including URLs.
Instead, PDF/A focuses on prohibiting the use of technical features in the PDF page description language (as defined by ISO 32000) that create external dependencies for page resources needed for rendering. This ensures that all images, fonts, ICC color profiles, and other resources are consistently embedded in PDF/A files to guarantee a reliable page appearance.
URI, URL, and URN
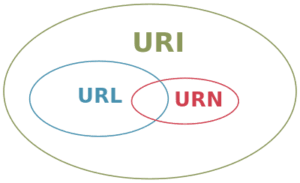
Any preservation policy should clearly define which types of “external references” require management. An understanding of URIs, URLs, and URNs (as documented in RFC 3986) is therefore needed.
- Uniform Resource Identifiers (URIs) are generic identifiers defined by a string of characters that identify a specific resource, but do not imply access based on the URI. A URI is not necessarily a URL.
- Uniform Resource Locators (URLs) are a type of URI that provides the location of a resource on the Internet and a means to access it. However, a URL is not guaranteed to exist.
- Uniform Resource Names (URNs) are another type of URI that names a resource, but does not imply the location exists or how to access it.
Some examples (similar to those in RFC 3986):
URL: ftp://ftp.is.co.za/rfc/rfc1808.txt
URL: https://www.ietf.org/rfc/rfc2396.txt
URL: mailto:John.Doe@example.com
URL: news:comp.infosystems.www.servers.unix
URL: telnet://192.0.2.16:80/
URN (not URL): urn:oasis:names:specification:docbook:dtd:xml:4.1.2
URN (not URL): tel:+1-816-555-1212
URI (not URL): http://ns.adobe.com/pdf/1.3/
URI (not URL): http://www.aiim.org/pdfa/ns/id/
For the remainder of this article, I’ve assumed that only URLs are of interest in supporting comprehensive preservation efforts.
External URL references
Authors can add URLs to content in various ways:
- As a URL in content, but without any hyperlink, where the content may be text, an image, or vector graphics.
- As hyperlinked content, where the hyperlink and displayed content (text, image, or vector graphics) are the same.
- As a hyperlink, where the hyperlink differs from the displayed content (text, image, or vector graphics).
Note that the link in hyperlinked content is not required to match the URL displayed.
The following simple HTML fragment illustrates some of these different content scenarios:
<html> <body> <p>This inline URL https://www.pdfa.org is just text and is not clickable. </p> <p>This text contains a <a href=”https://pdfa.org”>clickable URL</a> that is not visible. </p> <p>This text contains a clickable URL to <a href=”https://pdfa.org”>https://pdfa.org</a> that is also visible. </p> <p>This text contains a different clickable URL to <a href=”https://pdfa.org”>https://iso.org</a> that which is visible. </p> <a href="https://pdfa.org"> <img src="https://pdfa.org/wp-content/uploads/2018/12/pdf-association-logo-300x141.png" alt="A clickable image"> </a> </body> </html>
To discover all URLs in any document, software must examine both the content and all relevant features of the page description language, such as the href attribute of all HTML <a> tags.
In HTML, resources such as images, CSS style sheets, color profiles, or JavaScript code may contain “invisible” URLs as well as other URIs. For example, JPEG images may contain EXIF/IPTC metadata including URLs, while ICC color profile metadata may also contain URLs. JavaScript can be used to construct URLs programmatically. Although these URLs are not directly visible as content in a web browser, reviewing them may still be critical to comprehensive preservation efforts.
As PDF is a richer page description language than HTML, URLs in PDF can exist in features that do not have HTML equivalents. For example, PDF bookmarks (technically known as Outlines, ISO 32000-2, §12.3.3) may contain one or more URLs.
Comprehensive archival policies should identify which URLs (or URIs) are of interest, regardless of the file format used. This guidance should not make assumptions about authoring practices, as applications and methods for creating PDF and PDF/A files are subject to change over time.
Actionable URLs in PDF
In PDF, actionable hyperlinks to locations outside of the document are enabled via a technical feature known as Actions (see ISO 32000-2:2020, §12.6).
For hyperlinking content on a page, a Link annotation (ISO 32000-2, §12.5.6.5) is the PDF equivalent of the HTML <a> anchor tag, defining the clickable “hot zones” on a page. The destination (or target) for each Link Annotation is defined by either a Destination or a set of Actions. Destinations (ISO 32000-2, §12.3.2) are used for locations within PDF documents (and do not use URIs), while Actions (ISO 32000-2, §12.6) are a more powerful feature as they can refer to other PDF files, utilize JavaScript, or reference external URLs.
The PDF page description language defines a wide variety of action types that can be associated with various PDF features. However, PDF/A defines restrictions, such as which PDF features may use actions, and which action types are permitted. These restrictions simplify where URLs may be defined in conforming PDF/A files versus general PDF documents. For example, PDF/A prohibits the following action types: Launch, Sound, Movie, ResetForm, ImportData, Hide, Rendition, Trans, and all deprecated action types. Only PDF/A-4 permits JavaScript actions, but prohibits their automatic execution in PDF/A-conforming viewers (a user must explicitly invoke them).
The URI Action (ISO 32000-2, §12.6.4.8) will be of most interest to preservationists. The URI entry defines a UTF-8 encoded URI. For relative URIs, the URI entry in the document catalog defines a dictionary with a Base entry (ISO 32000-2, Table 211), which is prepended to the URI Action’s URI value to construct an absolute URI.
ISO 19005 standards do not restrict the use of Link annotations in PDF/A files - any restrictions encountered reflect a choice made by the respective PDF/A creation software.
Unlike in HTML, any PDF feature that supports actions in PDF/A can define a tree of actions. Thus, a single Link annotation on a page, or as a bookmark, can invoke multiple URLs.
Where can URLs exist in PDF/A files?
Comprehensively identifying all URLs in PDF/A files requires processing many PDF features beyond just page text content.
Page content
Content on PDF pages can include URLs just like HTML. PDF separates page content from the hyperlinking markup, which uses Link annotations. Thus, when considered in isolation, PDF page content is not hyperlinked.
Exceeding the capabilities of HTML, PDF supports active hyperlinking of mixed or partial content. In all cases, a Link annotation is required to define the “hot zone”. As with HTML, the URL in page content and in the Link annotation may be different.
To locate inactive URLs (that is, URLs without Link annotations), text in PDF pages can be extracted and examined. However, this approach will fail to locate URLs in vectorized text (where the text is rendered with vector graphics, as might occur during conversion to PDF due to font licensing restrictions). Such URLs can only be recognized using ActualText in Tagged PDF (ISO 32000-2, §14.9.4) or via OCR.
Many modern PDF viewers automatically detect and activate URLs in PDF page text content, even when no Link annotation is present. This behavior is not compliant with PDF/A; such software should include a preference setting allowing the user to turn off the automatic linking of URLs. Using PDF/A-conforming software will also restrict URL activation to those URLs that the document’s author intended to be active.
Annotations
As described above, Link annotations define the location and behavior of active hyperlinks in page content.
PDF annotations exist separately from page content and may not be processed by text extraction software. Most annotations in PDF/A conforming files are required to have an appearance stream, which may contain a URL (e.g., “sticky note” or text markup annotations might include URLs). Thus, all annotation appearance streams and all annotation Contents entries in PDF/A files also need to be examined for URLs.
Bookmarks
Commonly known as “bookmarks”, PDF Outlines (ISO 32000-2, §12.3.3) have no equivalent in HTML. Outlines leverage actions and thus may include a URI Action.
Document information dictionary
The document information dictionary contains PDF strings, which sometimes include URLs related to the creator or producer software. Metadata, such as document information dictionary entries, may also not be processed by text extraction software.
Metadata
XMP is an XML serialization of metadata defined by ISO 16684-1:2019. XMP data will contain many URIs for namespace definitions, but may also contain URLs.
JavaScript (ECMAScript)
PDF/A-1, PDF/A-2, and PDF/A-3 do not permit JavaScript actions; therefore, JavaScript cannot be present in files that conform to these standards.
PDF/A-4 permits JavaScript actions but prohibits their automatic execution (they may only be explicitly invoked by the user). For interactive forms, PDF/A-4 suggests the following (ISO 19005-4:2020, §6.4.1):
A conforming processor that removes JavaScript actions but still needs to store information about an interactive form’s values or logic (such as JavaScript actions) while maintaining PDF/A-4 conformance shall store that information as an embedded file stream (ISO 32000-2:2020, 7.11.4) in the EmbeddedFile name tree (ISO 32000-2:2020, 7.7.4) in XFDF format (ISO 19444-1). Its file specification dictionary shall contain an AFRelationship key with a value of FormData.
Therefore, examining the EmbeddedFile name tree for such JavaScript files may be necessary.
Nested resources
As with HTML, resources such as images, fonts, or ICC color profiles may contain “invisible” URLs as well as other URIs. For example, JPEG images may contain EXIF/IPTC metadata with URLs, while ICC color profile metadata may also contain URLs. Although these URLs are not directly visible as content in a PDF viewer, they may be critical to comprehensive preservation efforts.
Embedded files
PDF files may include embedded files that may contain URLs. A recursive process of examining all embedded files in PDF/A-conforming files is necessary. Note that PDF/A-1 prohibits embedded files.
Private data
Like most other file formats, including TIFF and HTML, PDF (and thus PDF/A) files may contain private data. Such private data may include “invisible” URIs that will not be visible in normal PDF viewers. See the PDF Association’s Application Note “Understanding private data in PDF/A” for more information.
Altering links
A common question pertains to the alteration of active hyperlink URLs in PDF/A documents. As mentioned above, PDF/A does not constrain content; therefore, PDF/A software is free to modify URLs within content when creating or modifying PDF/A files. This functionality may be desirable for anonymizing documents that contain tracking URLs or for converting archival documents to be inactive or “safe”.
As described above, active hyperlinks in PDF page content are enabled via Link annotations with associated URI action(s) containing the URLs. ISO 32000-2, Table 176 defines a PA key for Link annotations to store the original URI action with the original URL. The PA entry is not used for interactive hyperlinking. The Link annotation’s A entry, which defines the actions that will occur if a user clicks in the Link annotation’s “hot zones”, can then be changed to be a new URI action with a “safe” URI or a non-functional URL (e.g., “https:” is changed to “hxxps:”).
As an alternative to changing URLs, software could create additional content (pages) listing all original URLs (without Link annotations - so not hyperlinked) and a Go-To action (ISO 32000-2, §12.6.4.2) could then be used as the value of the Link annotation’s A entry to navigate to the appropriate – but inactive – list item. As noted above, many modern PDF viewers default to automatically detecting and activating URLs in PDF page text content, even when no Link annotation is defined in the PDF file. This behavior is not compliant with PDF/A, and therefore, changing the respective preference setting or using PDF/A-conforming software is necessary to prevent the activation of these potentially dangerous URLs in the added content.
Conclusion
Comprehensive preservation efforts can include identifying and reviewing all external URLs to “referenced content”. This process can assist preservation efforts by ensuring that, in addition to the preserved document itself, all related information is also adequately preserved or documented. The PDF/A file format requires that rendering resource dependencies for fonts, images, and color profiles are always embedded; however, it does not impose similar constraints on content. Thus, the process of examining a PDF/A document's content for external references (URLs) is an additional task, outside the scope of PDF/A validation. Comprehensive archival policy frameworks should therefore provide guidance on identifying which categories of URLs (or URIs) are of interest.
