


HuggingFace echoes SafeDocs
PDF in the WildJanuary 22, 2026
PDF in the WildJanuary 22, 2026
About PDF Association staff
HuggingFace echoes SafeDocs with new PDF datasets
A recent Huggingface blog explores PDF because the format is “a high-quality data for pretraining, and importantly a source of long-context documents so often missing from [HTML data]”.
In the AI trainer’s search for information, they note in particular the value of PDF to AI models because, as they say:
“Content that requires significant effort to create typically correlates with higher information density.”
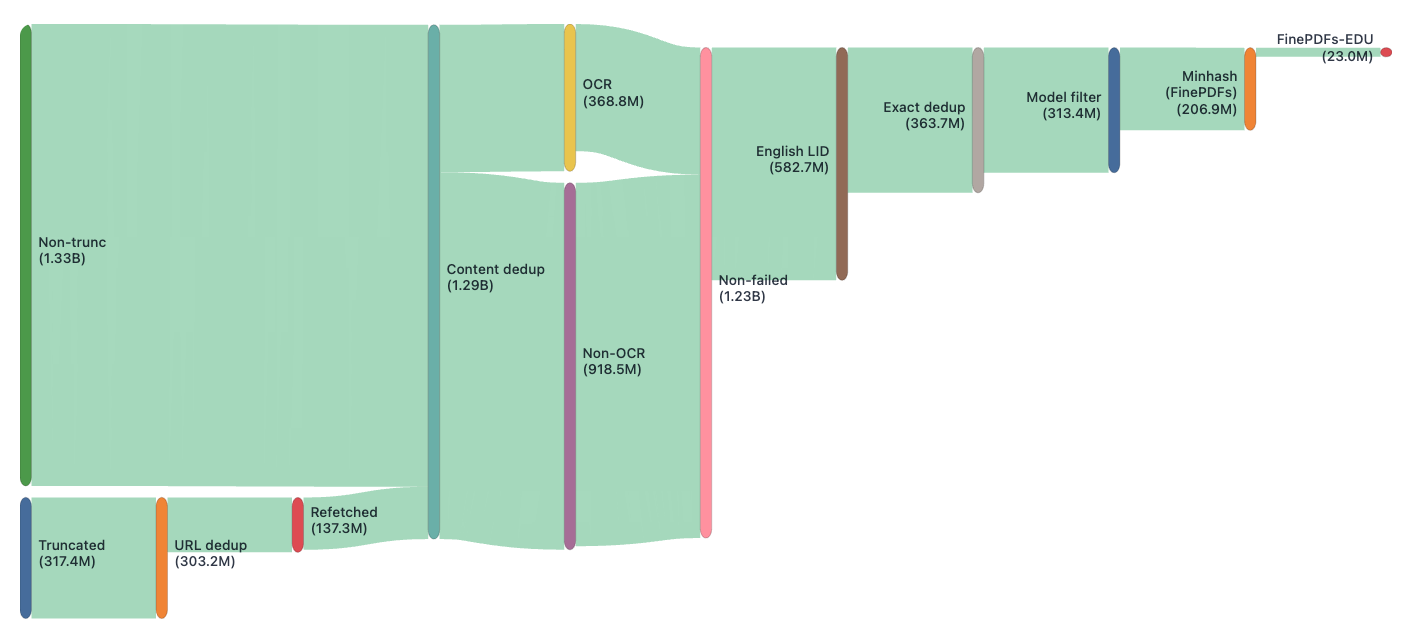
The blog post goes on to describe how HuggingFace identified truncation in the Common Crawl web archives and then refetched data in a process identical to the one previously described in the SafeDocs paper: Allison, T. et al. (2020) “Building a Wide Reach Corpus,” in LangSec 2020, Sixth Workshop on Language-Theoretic Security (LangSec) at the IEEE CS Security & Privacy Workshops, IEEE, (http://spw20.langsec.org/papers/corpus_LangSec2020.pdf). Unfortunately, the HuggingFace authors do not credit SafeDocs or reference this article, which was the original trigger for Common Crawl to increase its PDF truncation limit from 1MB to 5MB. The primary contribution from HuggingFace is the scale at which they can operate.
When it comes to extracting text, the article states that it’s a “nightmare”. While this may be true for certain document types, such as scans, the authors fail to mention Tagged PDFs, metadata, embedded files, or annotations, all of which provide additional semantic information that could benefit LLMs. The HuggingFace blog goes on to describe in detail the many and varied techniques they tried to solve this “nightmare”, resulting in their new “FinePDFs” and “FinePDFs-EDU” datasets.
FinePDFs is exactly that. It is the largest publicly available corpus sourced exclusively from PDFs, containing about 3 trillion tokens across 475 million documents in 1733 languages.
FinePDFs-Edu dataset consists of 350B+ tokens of educational PDFs filtered from FinePDFs dataset covering 69 languages.
Chrome does NOT sign or annotate your PDF!
But it will allow you to scrawl on it …
Google’s latest Chrome browser includes the ability to draw on a PDF. Here’s their video promoting the new feature:
However, it is a disservice to their users that the Chrome team has decided to promote this new PDF capability using the words “sign” and signature” as there are no electronic or digital signature capabilities.
This new feature simply allows users to manually draw on PDF pages.
We warn users NOT to be fooled into “signing” anything with Google Chrome – always use cryptographic PDF digital signatures for important or legally-binding documents.
Furthermore, the promotion and user interface of this new feature may mislead users into thinking it will leverage the rich and widely-supported PDF Annotations model, as the PDF Polygon and polyline annotation types defined in PDF 1.5 (introduced in 2003) provide the same features. However, this is sadly not the case.
Instead, Chrome “bakes” the drawn content into each PDF page’s content stream, using a marked-content sequence with the custom tag “GOOG:INKIsInker” (as defined here). This method not only invalidates PDFs with genuine digital signatures (by modifying the signed document), but also makes removing user scribbles from Google Chrome PDFs much more difficult for most users.
Further, as the Chrome team developed their own methodology, they haven’t provided any means to make the scribbles added with this tool accessible to users with disabilities. Using PDF annotations is one way in which accessibility could have been achieved.
ONIX application note
EDItEUR has released an ONIX application note on embedding ONIX metadata within a PDF.
Developed in collaboration with the PDF Association, this note builds on the PDF Association’s recent publication providing guidance for including custom metadata structures in PDF.
The note is designed for publishers who wish to include information for use with archiving and preservation, and especially (in the context of recent EU regulatory changes) to record the accessibility status of the PDF.
Download the new application note from EdItEUR.
After the PDF?
Will “knowledge objects” replace PDF? It’s a great idea, but we have to point out that there’s nothing about this vision that can’t be achieved with PDF.
There’s no need to invent a new format and (the hard part) sell the whole world on switching to it! Consider making smarter PDF files instead … and enjoy all the other benefits PDF delivers: reliability, authenticity, support for offline workflows, and more.
PDF-related ISO publications updates
ISO 19593-1 Processing Steps

The dated revision of ISO 19593-1 Graphic technology — Use of PDF to associate processing steps and content data — Part 1: Processing steps for packaging and labels has reached draft international standard (DIS) stage and is publicly available for comment.
This update replaces the 2018 edition with the main technical changes as follows:
- Additional processing-step groups and types are defined.
- Usage of the GTS_Metadata dictionary is allowed for OCGs (optional content groups) other than processing-step OCGs.
- Processing-step PDF object membership of multiple processing-step OCGs that have a different group and/or type is prohibited.
- It is recommended to include PDF objects that are not processing-step PDF objects in one or more OCGs.
PDF Week London 2026
ISO committee and PDF Association members: Don’t forget to reserve the dates of May 4-8 for PDF Week London.
PDFacademicBot for January 2026
The PDFacademicBot brings academic research on PDF and related technologies to the industry’s attention.
Dimmler, H.-R. (December 2025) “Information Extraction from Financial Tables: Application and Evaluation of a Machine Learning Approach in Annual Reports”. Master of Science thesis. FHNW University of Applied Sciences and Arts Northwestern Switzerland. Available at:https://irf.fhnw.ch/handle/11654/54840.
Dhamdhere, P. et al. (December 2025) “Document Summarizer: A Machine Learning Approach to PDF Summarization,” in K. Patil, F. Moreira, and S. Dash (eds.) Proceedings of the International Conference on Sustainable Innovation with Artificial Intelligence and Machine Learning 2025 (ICSIAIML 2025). Dordrecht: Atlantis Press International BV (Advances in Intelligent Systems Research), pp. 720–731. https://www.atlantis-press.com/article/126021200.pdf.
Ganapathiyappan, K. et al. (December 2025) “Advanced AI-Driven Cybersecurity Solutions: Intelligent Threat Detection, Explainability, and Adversarial Resilience,” Computers, Materials & Continua, 86(2), pp. 1–31. https://doi.org/10.32604/cmc.2025.070067.
Garg, N. et al. (2026) “Optical Character Recognition (OCR) with Text Generation Using Tesseract and PDF Editing Web Application Using Flask,” in M. Ali et al. (eds.) Hybrid Intelligence: Theories and Applications. Singapore: Springer Nature, pp. 547–557. https://doi.org/10.1007/978-981-96-7753-5_44.
Guerrero, A.C. et al. (December 2025) “PicAxe: Extracting Figures from Structurally and Syntactically Heterogeneous Corpora of PDF Files,” Journal of Open Research Software, 13(1). https://doi.org/10.5334/jors.574.
Hynek Kydlíček, Guilherme Penedo, and Leandro Von Werra (6 January 2026) FinePDFs: Liberating 3T of the finest tokens from PDFs - a Hugging Face Space by HuggingFaceFW, HuggingFace Blogs. https://huggingface.co/spaces/HuggingFaceFW/FinePDFsBlog.
Maťašová, S. et al. (November 2025) “Implementing AI techniques for efficient searching in document databases,” in 2025 International Conference on Emerging eLearning Technologies and Applications (ICETA). 2025 International Conference on Emerging eLearning Technologies and Applications (ICETA), pp. 578–585. https://doi.org/10.1109/ICETA67772.2025.11280102.
Mashkanov, A.S., Akhayeva, Z., and Zakirova, A. (December 2025) “Automated extraction and structuring of menus from PDF files using machine learning and NLP techniques,” Bulletin of L.N. Gumilyov Eurasian National University Technical Science and Technology Series, 153(4), pp. 257–267. https://bultech.enu.kz/index.php/main/article/view/980.
Michele Merico (2025) PDF Forensics and Attack Analysis: Development of a Unified Investigation Tool. Master’s Degree in Cybersecurity Engineering. POLYTECHNIC UNIVERSITY OF TURIN. Available at: https://webthesis.biblio.polito.it/secure/38692/1/tesi.pdf.
Mesengiser, Y.Y. et al. (December 2025) “On the practicality of attacks on electronic document management systems when signature keys are jointly used in TLS 1.2,” Problems of information security. Computer systems, 24(4), pp. 89–101. https://jisp.spbstu.ru/en/article/2025.24.7/.
Musmade, P. et al. (2026) “MIND MAP-BASED PDF SUMMARIZER,” International Journal of Engineering Science and Advanced Technology, 26(01), pp. 164–168. https://www.researchgate.net/profile/Devireddy-Maheswara-Reddy/publication/399528143_MIND_MAP-BASED_PDF_SUMMARIZER.
Olanrewaju, O.T. et al. (December 2025) “Integration of NaijaCaptcha System to an Intelligent PDF Reader with Translator,” University of Ibadan Journal of Science and Logics in ICT Research, 15(No. 1). https://journals.ui.edu.ng/index.php/uijslictr/article/view/2053.
Rahman, M.S. and Andrianingsih, A. (January 2026) “Adaptive Learning System Based on Human-in-the-Loop for PDF Template Data Extraction,” Sinkron : jurnal dan penelitian teknik informatika, 10(1), pp. 145–160. https://doi.org/10.33395/sinkron.v10i1.15598.
Velamala, R.R. (2026) “LocalRAG: A Privacy-Preserving Offline Framework for Multi-PDF Question Answering,” International Journal of Computer Applications Technology and Research, 15(1), p. 7. https://doi.org/10.7753/IJCATR1501.1003.
Rożej, K., Skonieczny, Ł. and Koperwas, J. (January 2026) “PDF accessibility in open repositories: A large-scale automated assessment,” Journal of Information Science. https://doi.org/10.1177/01655515251396902.
We’re very pleased to see that academic papers are now formally referencing up-to-date PDF Association materials such as the Matterhorn Protocol 1.1 referenced in the above publication!
Torang Siregar (January 2026) “Development of Flip PDF Corporate-Based E-Module on Sphere Surface Area and Volume Material.” https://zenodo.org/doi/10.5281/zenodo.18174364.
Vaderna, R. et al. (2026) “Enhancing Legal Document Security and Accessibility with TAF,” in. Network and Distributed System Security (NDSS) Symposium 2026, San Diego, CA, USA. https://ssl.engineering.nyu.edu/papers/vaderna_taf_ndss_2026.pdf.
