


Advanced mathematics for better (context aware) preflight
Member NewsApril 5, 2019

Member NewsApril 5, 2019

About Akash Choudhary,
The views expressed in this article are those of the author(s) and do not reflect the policies or positions of the PDF Association.
 Let me illustrate the problem first. On the right hand side, you can see a blue rectangle and a red circle. If I use a traditional preflight software on a document with this rectangle and circle, it can definitely (well considering it's a somewhat good software) answer questions like: whether there are any blue objects... whether there are any red objects... how many blue or red objects are there in this document... whether their colors are correct... whether the objects are of a particular type etc, because normal preflight looks at individual objects and their parameters on a page. This technique, needless to say, can detect A LOT OF problems in a PDF file but there are still a few questions that go unanswered.
Let me illustrate the problem first. On the right hand side, you can see a blue rectangle and a red circle. If I use a traditional preflight software on a document with this rectangle and circle, it can definitely (well considering it's a somewhat good software) answer questions like: whether there are any blue objects... whether there are any red objects... how many blue or red objects are there in this document... whether their colors are correct... whether the objects are of a particular type etc, because normal preflight looks at individual objects and their parameters on a page. This technique, needless to say, can detect A LOT OF problems in a PDF file but there are still a few questions that go unanswered.
Now that we are talking about problems, let's talk about one more. Small black text will often be set to overprint to accommodate effects of slight mis-registration in the printing process (figure below): if such small text where to knock out content behind it, small but very noticeable white lines might show up around the text. Many preflight configurations will flag small text that is not set to overprint. In many cases though, such text does not have any content underneath it – it then simply does not matter whether that small text is set to overprint or to knockout.

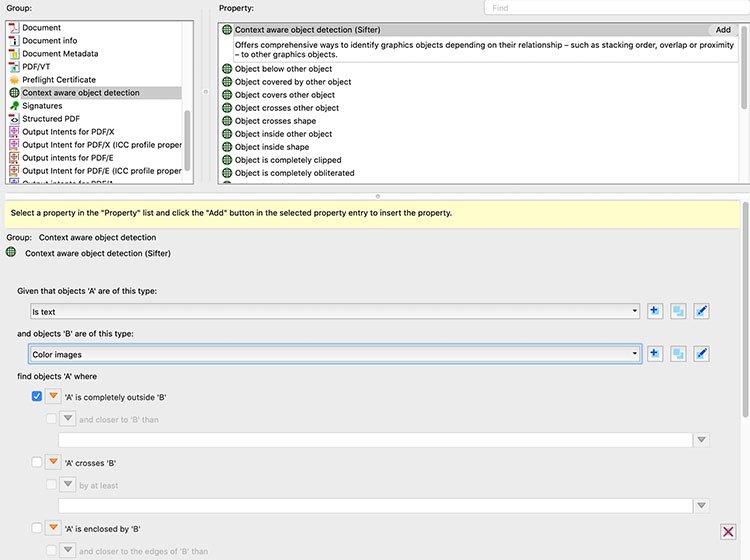
Is it possible with traditional Preflight to flag small text not set to overprint in cases where it does have visible content underneath it? The answer is NO, it cannot. It will simply look at each object individually but fails to test a relationship between two objects. This is exactly why context aware object detection technology was invented. It looks at relationships between objects and as you all might know, relationships can be COMPLICATED, as described below:
- Stacking order: whether one object is drawn before or after other objects;
- Intersection: whether an object shares a certain area of the page with other objects, or an arbitrary area on the page,
- Insideness: whether an object is inside or outside other objects, or an arbitrarily shaped area on the page
- Proximity: how close an object is to other objects or the border of an arbitrarily shaped area on the page
- Clipping: whether an object is partially or fully clipped
- Obliteration: whether an object is partially or fully covered by other opaque objects
Just imagine a complex combination of the above mentioned relationships between different objects in a PDF file. Let's say a file with CAD generated drawing having 10.000 objects and 1.000 out of those are the objects of interest. Now the engine has to check all the relationships with the other 9.000 objects. You can already imagine that the biggest problem during development was still not the calculations itself, but to perform them in an acceptable time.
One major advantage of this new technology comes from real life examples where you can avoid a lot of false positives in your automated workflow and get the hits that you actually need. By doing so, the number of documents that can flow through automatically from being 'received' to being 'printed' becomes higher. Or you can say that the percentage of documents that are stopped from fully automated printing will be much lower OR the percentage of documents that are stopped CORRECTLY will be much higher. In a world of more and more digital printing, ever tighter deadlines, increased levels of automation, more demanding print buyers and fast growing challenges in more and more complex production setups, this technology can be very helpful. Think of scenarios where you have to find and remove invisible graphics objects, find text too close to a line of interest, find non-print spot color objects that are behind other objects and could get knocked out or even check for light thin lines against dark background. If you can, then context sensitive object detection is what you need.
pdfToolbox 10 has introduced context aware object detection with the term “Sifter” technology. You should, however, take the performance penalty that comes with Sifter into account when using it in Profiles: E.g. you might not want to check any objects that are fully covered by other objects - but you should not add a check to each of your rules that finds out whether the object is covered, simply because that will have a huge impact on performance. What you should rather use is Sifter to safely remove such objects, which, with regards to performance, is much “cheaper”.
From continued research and implementation cycles, callas software's Sifter technology emerged as the engine, that provides extensive context aware checking capabilities at the speed mandated by today's workflows. Sifter is an integral part of callas pdfToolbox starting with version 10, and is equally available in the desktop, server, command line and SDK variants of callas pdfToolbox on Apple MacOS, Microsoft Windows and Linux operating systems.
callas software was founded in 1995 and has focused on making PDF files usable in production environments from the start. While PDF was designed as a flexible and open format, using it reliably in production – where standardization matters – often proves challenging. callas develops technology to identify PDF files…
Read more