

Browsers battle over PDF capabilities
PDF in the WildJuly 17, 2025
PDF in the WildJuly 17, 2025
About PDF Association staff
ISO/IEC removes “Publicly Available Standards” page
We’ve noticed that ISO has removed the “Publicly Available Standards” page at https://standards.iso.org/ittf/PubliclyAvailableStandards/index.html, which had provided a handy one-stop webpage for easy access to all free (so called “no charge”) ISO/IEC standards prepared by various ISO/IEC JTC 1 subcommittees. Many of these free standards are referenced by PDF specifications.
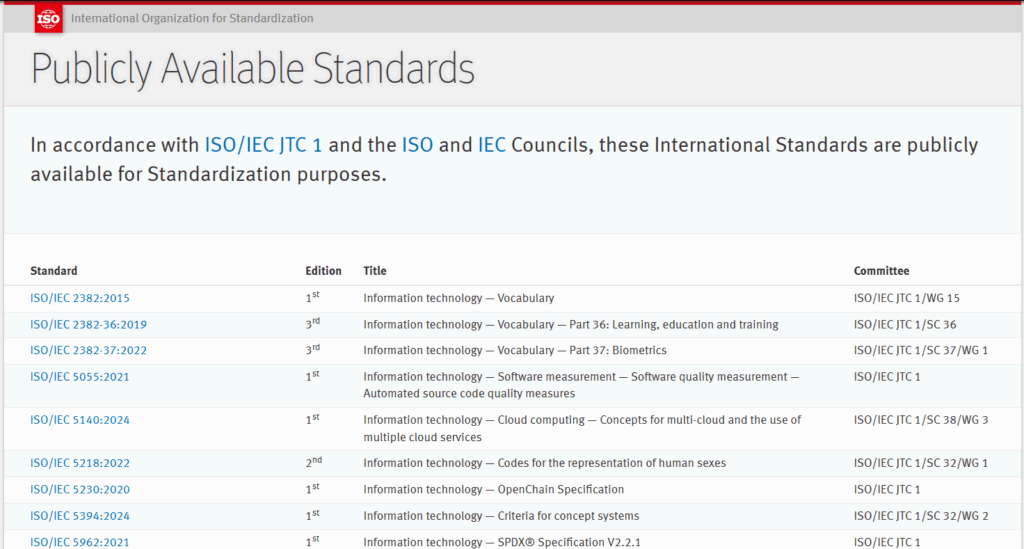
ISO/IEC now requires every user to register with an ISO account, locate each ISO standard at https://www.iso.org/store.html (or the IEC equivalent), go through the full purchase process (for 0 CHF) for each standard, log in to your ISO account, and assign each standard before being able to download a personalized watermarked PDF. Once “purchased”, the free standards can be downloaded from your account in the future.
So far as we can tell, the only upside (for the user) of this lengthy and convoluted process is the opportunity to opt in to receive notifications of any changes to the free standards you have “purchased”.
As a result, we have also updated our annotated page listing all references from ISO 32000-2:2020 (the latest PDF 2.0 specification).
Browsers battle over PDF capabilities
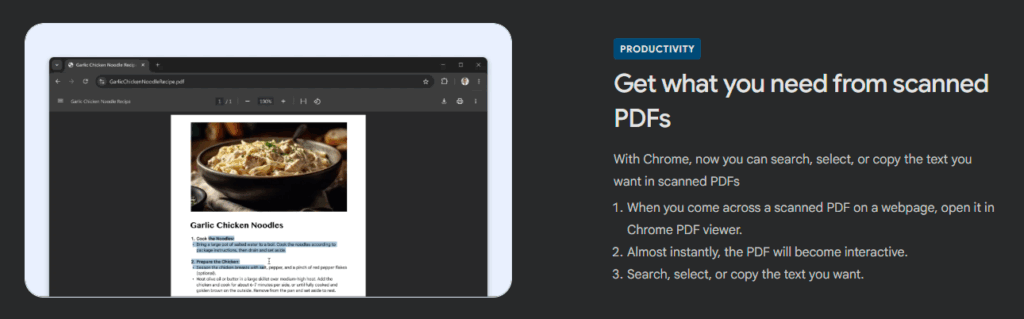
The Google Chrome update to Version 138.0.7204.50 promotes its capabilities to make textual information in “scanned PDFs” available…
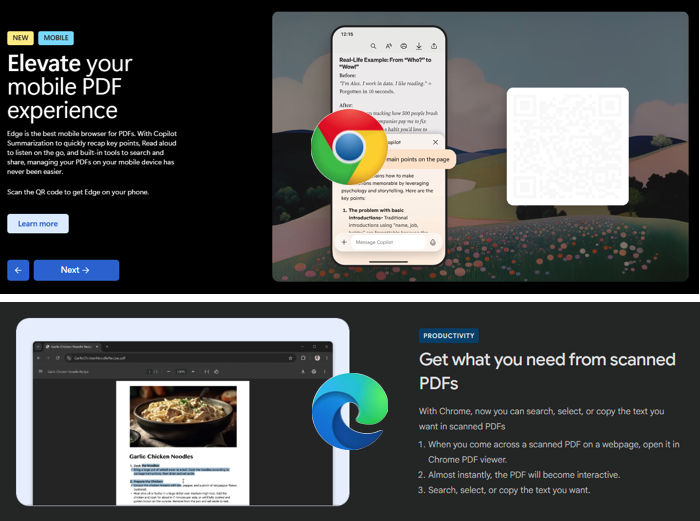
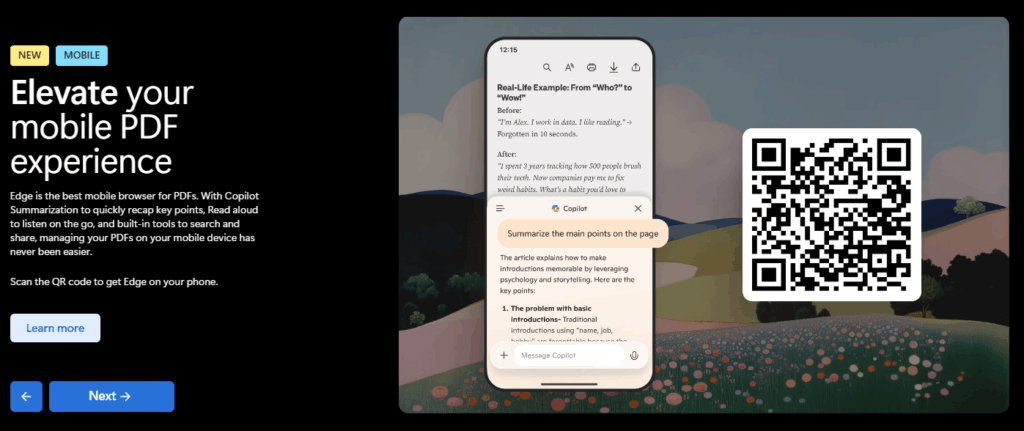
Meanwhile, Microsoft Edge’s update to Version 138.0.3351.55 promotes its improved mobile PDF experience:
We went one step further and asked Microsoft’s Copilot AI in Edge: “Which web browser has the best built-in PDF technology?”. Not unsurprisingly, here is what it replied:
When it comes to built-in PDF capabilities, Microsoft Edge consistently stands out. It offers a robust set of features that go beyond basic viewing — like form filling, annotation with digital ink, text-to-speech ("Read Aloud"), digital signatures, and even support for accessibility tools. These features make it especially handy for users who regularly interact with PDFs but don’t want to install separate software.
Google Chrome is fast and integrates well with Google Drive, making it convenient for users in the Google ecosystem. However, its PDF tools are more limited—great for reading and printing, but not much else.
Mozilla Firefox also has a solid PDF viewer with customization options and accessibility features, but it doesn’t quite match Edge’s depth of tools.
If you're just reading PDFs, any modern browser will do. But if you're filling out forms, signing documents, or annotating files, Edge is hard to beat. Want help setting it up or exploring its features?
ChatGPT 4.0 gave a different response with different reasoning and recommendations, but also confidently asserted some very clear fallacies (not reproduced here, and which some might call “hallucinations”). ChatGPT concluded with the following, which importantly considers accessibility:
As of 2025, Google Chrome generally offers the most robust built-in PDF technology among major web browsers. Here's a comparison of leading browsers based on their PDF capabilities:
Browser Rendering Engine Best For Key Limitation Chrome PDFium Speed and fidelity Limited accessibility tools Edge PDFium+Extras Annotation, enterprise Bulkier interface Firefox PDF.js Open-source, privacy Fewer features Safari PDFKit macOS/iOS users Poor interactivity support If you're prioritizing accuracy, performance, and general usability, Chrome or Edge are the best choices.
“PDF to Brainrot” TikTok trend
Many TikTok users refer to videos with monotonic automated voices reading dramatic stories over calming videos as “brainrot” material, as they can be unusually addictive to watch/listen. A new trend is emerging with “PDF to Brainrot” generators, which read textbooks in the same robotic voice over these videos as a new way to help students study.
Some tools, like StudyRot, are also trained to translate text into Gen Z slang (you can choose from voices like “Sam Sigma,” “Gabi Gyatt,” or “Sara Skibidi,” referring to somewhat meaningless words that are popular among young people who spend a lot of time online). But giving the AI too much liberty to manipulate the source text is probably not a great study strategy, since you might end up with inaccurate summations; did Odysseus really have rizz, or was he a sigma male? (Plus, uploading content to AI tools that are not explicit about whether they might train on that data is generally not a good idea.)
If nothing else, we hope this can only further encourage educational publishers to ensure that all their PDF textbooks are Well Tagged PDF so that the automated reading correctly follows the logical structure in natural reading order, meaningful alt-text, MathML, etc., to actually educate students correctly!
JHOVE 1.34 update supports PDF 2.0
The Open Preservation Foundation (OPF) announced the release of JHOVE 1.34, providing identification of PDF 2.0, better validation of PDF dates, and improved reporting for invalid object numbers (such as objects with object numbers greater than the trailer Size entry).
EA-PDF: the US Library of Congress updates its guidance
The latest blog post on The Signal, from the US Library of Congress updates the Library’s guidance regarding metadata for email collections to better align with the PDF Association's EA-PDF specification.
PDF crossword fun
We had some fun putting together a simple crossword with clues based on PDF! How well do you know your PDF?
Alberta aligns with PDF 2.0 by dropping XFA
Looking for an ISO-standardized solution, in alignment with ISO 32000-2 (PDF 2.0), the Canadian province of Alberta is dropping XFA forms (LinkedIn). Let’s hope Alberta doesn’t throw the PDF baby out with the XFA bathwater!
A potted history of PDF
Although there are several summarized histories of PDF on the internet, we enjoyed this one at Tedium.co because it includes a contribution from the PDF Association!
ISO standardizes HDR gain-maps
ISO 21496-1 Digital photography — Gain map metadata for image conversion — Part 1: Dynamic range conversion has completed its development through ISO TC 42 WG 23 and is now a published ISO international standard:
This document defines a gain map used in HDR digital photography applications, for dynamic range conversion between two image representations. This includes the definition of the gain map metadata and its attributes, how to specify the gain map and associated metadata, and how to apply the gain map using this metadata.
The PDF Association is a Category A Liaison with ISO TC 42 “Photography” and contributed comments to this standard.
veraPDF 1.28.2 released
The Open Preservation Foundation (OPF) announced the release of veraPDF version 1.28.2. veraPDF is an open-source, industry-supported PDF/A, PDF/UA, and Well Tagged PDF validators, and an Arlington-based checker. This release includes corrections for many issues across the full range of veraPDF technologies.
Did you know???

PDFacademicBot for July 2025
Boukhers, Z. and Yang, C. (June 2025) ‘MESD: Metadata Extraction from Scholarly Documents -- A Shared Task Overview’, in. 2nd International Workshop on Natural Scientific Language Processing and Research Knowledge Graphs (Portorož, Slovenia), p. 9. https://ceur-ws.org/Vol-3977/NSLP-06.pdf.
Castagnaro, A. et al. (2025) ‘The Hidden Threat in Plain Text: Attacking RAG Data Loaders’. arXiv. https://doi.org/10.48550/arXiv.2507.05093.
Cheng, H. et al. (2023) ‘M6Doc: A Large-Scale Multi-Format, Multi-Type, Multi-Layout, Multi-Language, Multi-Annotation Category Dataset for Modern Document Layout Analysis’, in. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 15138–15147. Available at: https://openaccess.thecvf.com/content/CVPR2023/html/Cheng_M6Doc_A_Large-Scale_Multi-Format_Multi-Type_Multi-Layout_Multi-Language_Multi-Annotation_Category_Dataset_CVPR_2023_paper.html
Gema Fernández Bascuñana (2017) Method for Effective PDF Files Manipulation Detection. Masters of Cyber Security. University of Tartu, Estonia. Master's of Cyber Security Thesis. https://dspace.ut.ee/server/api/core/bitstreams/4980cf5f-addb-44f7-a26c-b8db27f3e39c/content.
Frank Gulban (June 2025) ‘Just publish the PDF: On the perils of being understood in science – things-on-things’, 11 June. https://thingsonthings.org/just-publish-the-pdf/
Grobler, G., Makura, S. and Venter, H. (July 2025) ‘A Technique for the Detection of PDF Tampering or Forgery’. arXiv. https://doi.org/10.48550/arXiv.2507.00827.
Hoang, T.T.U. and Nguyen, V.A. (June 2025) ‘PDF Retrieval Augmented Question Answering’. arXiv. https://doi.org/10.48550/arXiv.2506.18027.
Lade, S. et al. (2025) ‘System Design and Analysis for AI-Based Document Assistant’, in M.S. Uddin and J.C. Bansal (eds) Proceedings of International Joint Conference on Advances in Computational Intelligence. Singapore: Springer Nature, pp. 95–107. https://doi.org/10.1007/978-981-96-3741-6_8.
Levich, S. and Knust, L. (Dec. 2025) ‘Discriminative meets generative: Automated information retrieval from unstructured corporate documents via (large) language models’, International Journal of Accounting Information Systems, Vol. 56. https://doi.org/10.1016/j.accinf.2025.100750.
Lin, C. et al. (April 2025) ‘Knowledge Extraction and Structured Processing of Technical Standard PDF Documents’, in 2025 10th International Conference on Cloud Computing and Big Data Analytics (ICCCBDA), pp. 686–692. IEEE. https://doi.org/10.1109/ICCCBDA64898.2025.11030496.
Liu, S. et al. (June 2025) ‘Analyzing PDFs like Binaries: Adversarially Robust PDF Malware Analysis via Intermediate Representation and Language Model’. Accepted for ACM Computer and Communications Security (CCS) 2025. https://doi.org/10.1145/3719027.3744829.
Sayeed, H.M., Clark, C. and Sparks, T. (June 2025) ‘KnowMat: Transforming Unstructured Material Science Literature into Structured Knowledge’. ChemRxiv. https://doi.org/10.26434/chemrxiv-2025-l296q.
Sobhan, S. and Haque, M.A. (June 2025) ‘LLM-Assisted Question-Answering on Technical Documents Using Structured Data-Aware Retrieval Augmented Generation’. arXiv preprint. https://doi.org/10.48550/arXiv.2506.23136.
Vist, G.E. et al. (July 2025) ‘ExtractPDF: A data extraction tool for scientific papers applied to a systematic scoping review in public health’, Computer Methods and Programs in Biomedicine, Vol. 270. https://doi.org/10.1016/j.cmpb.2025.108962.
Xu, W. and Ibrayim, M. (June 2025) ‘An Advanced Unimodal Approach to Solving Complex Document Layout Analysis Tasks’, Signal, Image and Video Processing, 19(10), p. 794. https://doi.org/10.1007/s11760-025-04422-y.
