


What you may be missing when you search PDF documents
ArticleFebruary 11, 2016

ArticleFebruary 11, 2016

About Duff Johnson, PDF Association
PDF documents represent the bulk of newer content stored in ECM systems and cloud storage worldwide. PDF is replacing TIFF as the output format of choice for imaging systems, and there’s simply no substitute for PDF when it comes to creating a shareable record of static electronic content.
When searching PDF documents really matters
Documents are often used in lawsuits and similar expensive activities. In these cases, the ability to reliably search for keywords and phrases, personally identifiable information (PII), trade-secrets or any sort of sensitive material is fundamental to understanding your risks.
How text extraction and search software contributes to information-management risks
Consider the following examples:
Discovery: During the document discovery process that precedes litigation, text-extraction and search processes are used to locate “responsive” documents, i.e., those that must be turned over to opposing counsel. Failure to turn over a responsive document can create numerous expensive problems if discovered later in the proceedings. Attorneys like to know what they've got.
FOIA: Freedom of Information Act procedures includes searches of extracted text to speed the identification and removal of sensitive information ranging from PII to classified data. Even so, FOIA requests are a typical channel for data breaches, as this otherwise unremarkable example makes clear.
Most of today’s text-extraction tools have serious limitations when it comes to supporting reliable searching of PDF files because they don’t actually account for the document – they simply provide the ability to search the file. There’s a huge difference, as I’ll explain.
The challenges PDF presents to text-searching
At its heart, the PDF file-format is all about painting things onto pages, also known as “rendering”. There’s far more to PDF, of course, but that’s the core of it. As a result, PDF documents don’t always work precisely as one might expect when they are used for purposes other than rendering ... such as searching.
Let’s look at one common problem. It requires a brief dip into the guts of PDF, but not too far, and it’s illustrative.
What you see isn’t always what you search
PDF is extremely flexible. It’s commonplace (and sometimes essential) for software to create PDF files in which the ordering of text in the file (the “content order”) differs from the text’s appearance on the page (the “logical reading order”).
In Example 1, the content order is portrayed to the left. The orange arrow shows the order in which the text occurs in the file itself, which obviously differs from the way a human reads the page.
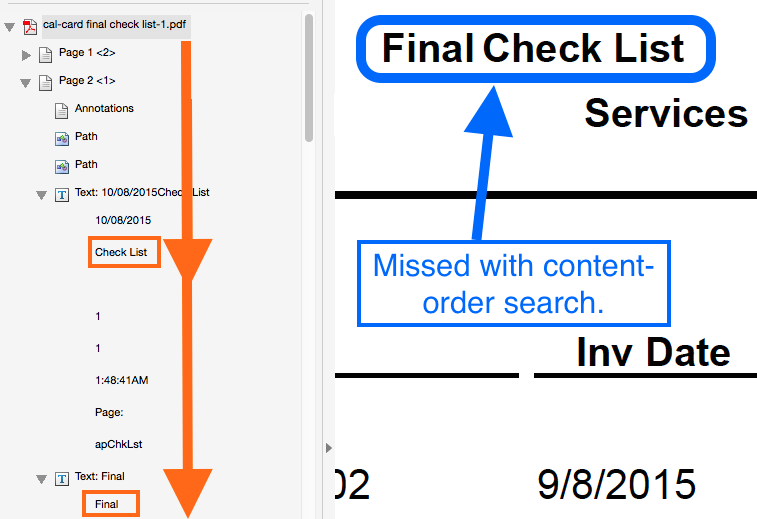
When reading the page visually, the logical reading order is what matters. When extracting text or searching, however, if the software uses the content order (how the PDF file is made) instead of the logical reading order (what's displayed on the page), your results may be affected.
Using most currently-available tools, including Adobe Acrobat, other PDF viewers and the server-side text extraction and search features in ECM systems, searching this PDF for “final check” will not find that phrase even though it’s plainly present on the page.
The reason is straight-forward: the text extraction and/or search software is using the file’s content order, not the logical reading order.
Example 2 shows a document that’s visually identical to the previous example. In this case the content order matches the human reader’s expectations. Accordingly, a content-order search for “final check” or “final check list” will work.
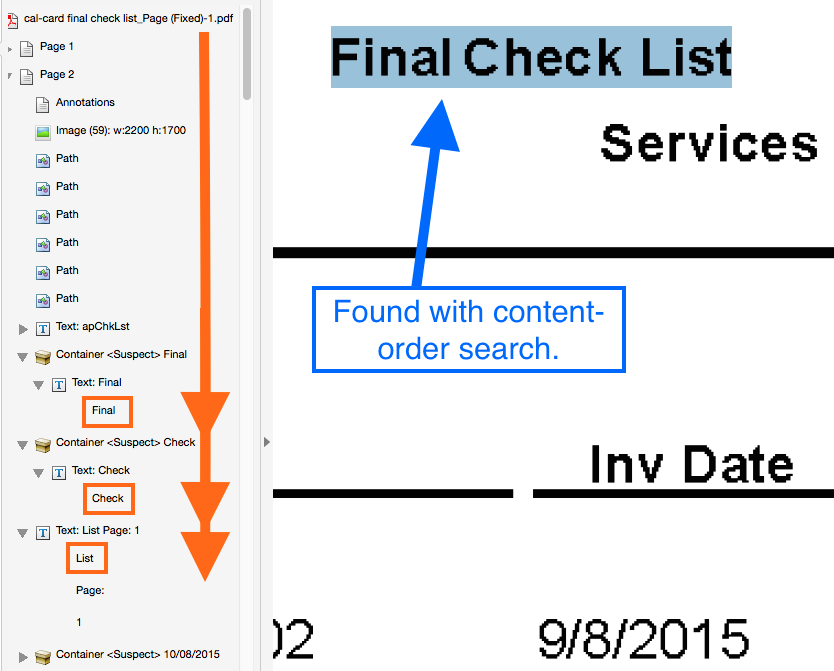
Both PDF documents look identical on-screen and in-print– but the guts of the files are quite different.
What’s the solution?
Few organizations can control the technical details of the documents they receive or create. PDF documents can and will include variations in the way text is encoded into the file, and sometimes these variations affect searchability.
If reviewers and other downstream procedures rely on text-extraction or search that uses only the content order, some hits will be missed.
To address this problem ECM customers and others who need to trust their text extraction and search systems can take the following steps:
- Don’t blame the documents or their authors. The problem can only be resolved with improved text extraction and/or search software.
- Insist that your text extraction or search engine provider include the following features:
- The ability to search the “logical order” of PDF files as defined by tagged PDF, and
- When tagged PDF is not available, provide heuristic analysis to determine a logical reading order.
Text extraction and search software developers have many choices about how they index PDF files. It’s up to ECM and other customers to demand software that does the right thing ... or risk the reality that some searches will fail to find each instance.
Can you solve the problem by just converting everything to TIFF and OCRing?
Although often defeating simpler text-ordering problems, reducing PDF documents to images in order to OCR them for will introduce new errors and cause more text to be missed in many relatively common circumstances:
- Complex layouts, including tables and diagrams
- Pages with inverted text (white text on colored backgrounds)
- Pages where text overlays images (common in publications)
- Text with very small typefaces, or rendered in pale colors
Don’t believe it? Check for yourself ...
Comparing text-extraction from PDF vs. OCR is easy enough to check for yourself. Take an arbitrary collection of PDF documents, extract all the text and count the words that result. Next, convert the PDFs to images and run OCR. The OCR process will (unless all pages in the example were from simple business documents) find significantly fewer words.
Conclusion
Today, both desktop and server-side ECM text extraction and search technology typically rests on assumptions rooted in the era of TIFF images and plain-text.
To manage exposure to the release of PII, company secrets, national security data and many other types of sensitive information, ECM customers who rely on PDF for electronic records should strongly consider reviewing the ability of their ECM systems to capture and search text from PDF documents.
