

Browsers leverage PDF in their battle for dominance
PDF in the WildNovember 18, 2025

PDF in the WildNovember 18, 2025
About PDF Association staff
Browsers leverage PDF in their battle for dominance
Recent browser releases have all promoted enhanced experience with PDF files. From accessibility to commenting and markup annotations, to leveraging AI, integrated PDF support in web browsers continues to be a competitive battlefield.
We just wish they would also get the basics right, such as support for bookmarks (missing from Safari), supporting embedded files (zero support in Chrome and limited support in Firefox), and supporting all PDF fragment identifiers as officially documented in RFC 8118.
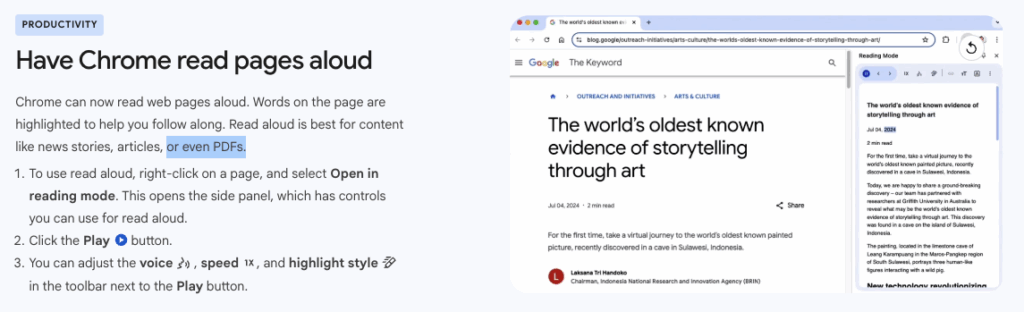
Chrome reads PDF pages aloud
Google Chrome version 142.0.7444.60 (Official Build) (64-bit) had this to say on chrome://whats-new/:
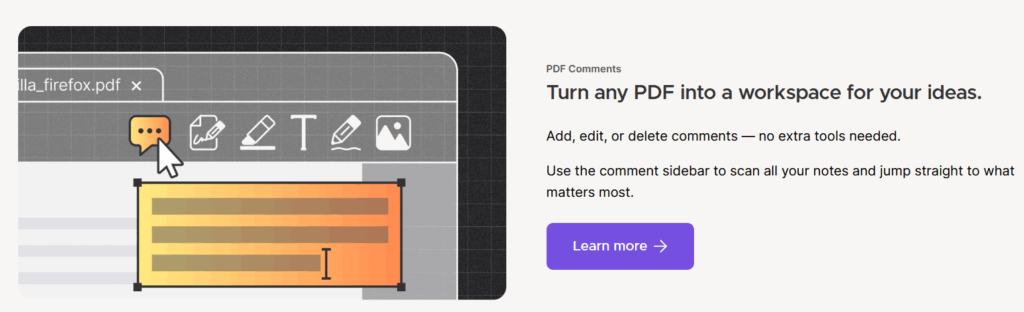
Firefox v145 expands PDF capabilities
In other browser news, the venerable Mozilla FireFox has added substantial new support for PDF, including support for creating and editing PDF annotations.
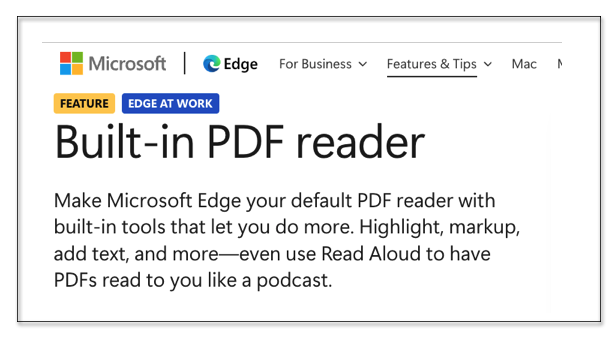
…and even Microsoft Edge promotes its PDF capabilities
Your PDF says a lot about you
We’re always interested in the ways in which the Portable Document Format intersects with popular culture. We recently learned, for example… well, we’ll just share what we found, and let you decide what it means!
Is Big Data finally getting smarter about PDF? Hmm…
According to VentureBeat “..approximately 80% of enterprise knowledge remains locked in PDFs, reports and diagrams that AI systems struggle to accurately process and understand. … enterprise PDFs are inherently complex. They mix digital-native content with scanned pages and photos of physical documents, alongside tables, charts and irregular layouts, and most existing tools fail to capture that information accurately.”
We agree that this complexity is real and at the heart of improving AI’s understanding of real document content, but we’re far less sure about the headline quote from Databricks stating that “PDF parsing for agentic AI is still unsolved”.
With trillions of extant files over 32 years in the field, a published specification for all of that time, and as an open ISO standard since 2008, how to correctly parse PDF is not exactly a well-kept secret. Big data companies sweating bullets over PDF complexity might consider joining the worldwide PDF industry association (that’s us, if you hadn’t guessed) so that they can gain insights into what they’re actually missing, which is all part of the Dunning-Kruger effect (from their 1999 paper “Unskilled and unaware of it: how difficulties in recognizing one's own incompetence lead to inflated self-assessments”).
For government, accessible PDF is the law
A new report – Beyond Compliance: The Economic Case for Digital Accessibility – by the US National Chief Information Officers of the States explicitly mentions a legal case involving inaccessible PDFs:
“A legally blind individual settled with a county government for $15,700 after being unable to access online public records due to inaccessible PDFs. The county must now ensure its website meets accessibility standards.”
Register-ing JPEG-XL for PDF
CTO Peter Wyatt’s “Breaking Good” presentation at PDF Days Europe in September is getting noticed in the tech press.
Prank PDFs (can) cause hallucinations
Naive ingestion systems allow tricksters to leverage PDF’s rich capabilities to spoof various AIs. Apparently, with at least some systems, even ridiculously simple tricks like transparent text – as demonstrated here – can turn an otherwise innocuous content into digital LSD!
C’mon folks. This is the sort of stuff that used to spoof search engines, but their policies changed 20+ years ago!
“Spiked” PDF
Prank PDFs aside, some professors have figured out how to leverage AI’s (current) naivete to good effect when catching out students who try to cheat. 😂
JAWS misses opportunity to improve accessible PDF support
We looked in vain for evidence that the venerable screen-reader JAWS is improving its PDF support with its latest release. Sadly, there’s nothing new for PDF in JAWS 2026, even though LaTeX and others are already producing PDF files with accessible math!
OpenPDF 3.0.0 supports PDF 2.0
The latest 3.0.0 major release of the OpenPDF OSS JAVA library now supports PDF 2.0. Congratulations!
PDFacademicBot for November 2025
The PDFacademicBot brings academic research on PDF and related technologies to the industry’s attention.
Aggarwal, V. et al. (Nov. 2025) “Information Extraction from Fiscal Documents using LLMs”. Working paper 43. xKDR. https://EconPapers.repec.org/RePEc:anf:wpaper:43
Bansal, R. et al. (2025) “OPTIMIZING PDF INGESTION FOR LARGE LANGUAGE MODELS IN RAG ARCHITECTURES,” International Journal of Applied Mathematics, 38(3s), pp. 18. https://ijamjournal.org/ijam/publication/index.php/ijam/article/download/163/154
Chinchmalatpure, S. et al. (2025) “AI-Driven PDF Translation: Ensuring Accuracy, Efficiency, and Integrity,” in J.K. Katiyar et al. (eds.) Proceedings of International Conference on Computer Science and Communication Engineering (ICCSCE 2025). Dordrecht: Atlantis Press International BV (Advances in Computer Science Research), pp. 966–977. https://doi.org/10.2991/978-94-6463-858-5_81.
Fischer, U. and Mittelbach, F. (October 2025) “News from the LATEX Tagged PDF project: 2025,” TUGboat (TeX Users Group Journal), 46(2), pp. 244-247. https://www.latex-project.org/publications/2025-UFi-FMi-TUB-tb143fischer-tagging25.pdf
Kang, H. et al. (October 2025) “OmniLayout: Enabling Coarse-to-Fine Learning with LLMs for Universal Document Layout Generation.” arXiv. https://doi.org/10.48550/arXiv.2510.26213.
Nguyen, N.B., Kammermann, L. and Hanne, T. (August 2025) “Evaluating Large Language Models for Table Data Extraction from Annual Reports in PDF,” Journal of Advances in Information Technology, 16(8), pp. 1118–1126. https://doi.org/10.12720/jait.16.8.1118-1126.
R, G. and Mishra, P. (October 2025) “Securing E-Governance: A Blockchain-Based Framework for Tamper-Proof PDF Document Exchange,” Frontiers in Blockchain, Vol. 8. https://www.frontiersin.org/journals/blockchain/articles/10.3389/fbloc.2025.1699773/full
Mowar, P., Steinfeld, A. and Bigham, J.P. (October 2025) “We Write Our Research Papers in WYSIWYM. Why Do We Tag Our PDFs in WYSIWYG?,” poster at 27th International ACM SIGACCESS Conference on Computers and Accessibility. New York, NY, USA: Association for Computing Machinery (ASSETS ’25), pp. 1–5. https://doi.org/10.1145/3663547.3759730.
Sangha, S.S. and Walz, A.R. (October 2025) “Transforming LaTeX to Accessible and Inclusive Formats: A Guide for Open Educational Resources,” Journal of Open Educational Resources in Higher Education, 3(3). https://doi.org/10.31274/joerhe.19769.
Shehzadi, T. et al. (October 2025) “DocSemi: Efficient Document Layout Analysis with Guided Queries,” in IEEE International Conference on Computer Vision Workshops, Computer Vision Foundation. https://openaccess.thecvf.com/content/ICCV2025W/VisionDocs/papers/Shehzadi_DocSemi_Efficient_Document_Layout_Analysis_with_Guided_Queries_ICCVW_2025_paper.pdf.
Thakur, A. et al. (2025) “Automated Invoice Data Extraction: Using LLM and OCR.” arXiv. https://doi.org/10.48550/arXiv.2511.05547.
Yamano, M., Fukuoka, K. and Miyamori, H. (2025) “Two-Stage Approach Using Pretrained Language Models for Question Answering on Japanese Document Images,” in Proceedings of the 33rd ACM International Conference on Multimedia. MM ’25: The 33rd ACM International Conference on Multimedia, Dublin, Ireland: ACM, pp. 13791–13796. https://doi.org/10.1145/3746027.3761998.
Zhu, Y. et al. (2025) “Towards Generalized Physical Occlusion Detection On Documents,” in Proceedings of the 33rd ACM International Conference on Multimedia. New York, NY, USA: Association for Computing Machinery (MM ’25), pp. 7596–7605. https://doi.org/10.1145/3746027.3754975.
