


ChatGPT can do magic, but doesn’t solve problems when extracting text from PDF
PDF in the WildAugust 11, 2023
PDF in the WildAugust 11, 2023
About PDF Association staff
What about offline AI for offline PDFs? Some claim that reading PDF pages will be a thing of the past.
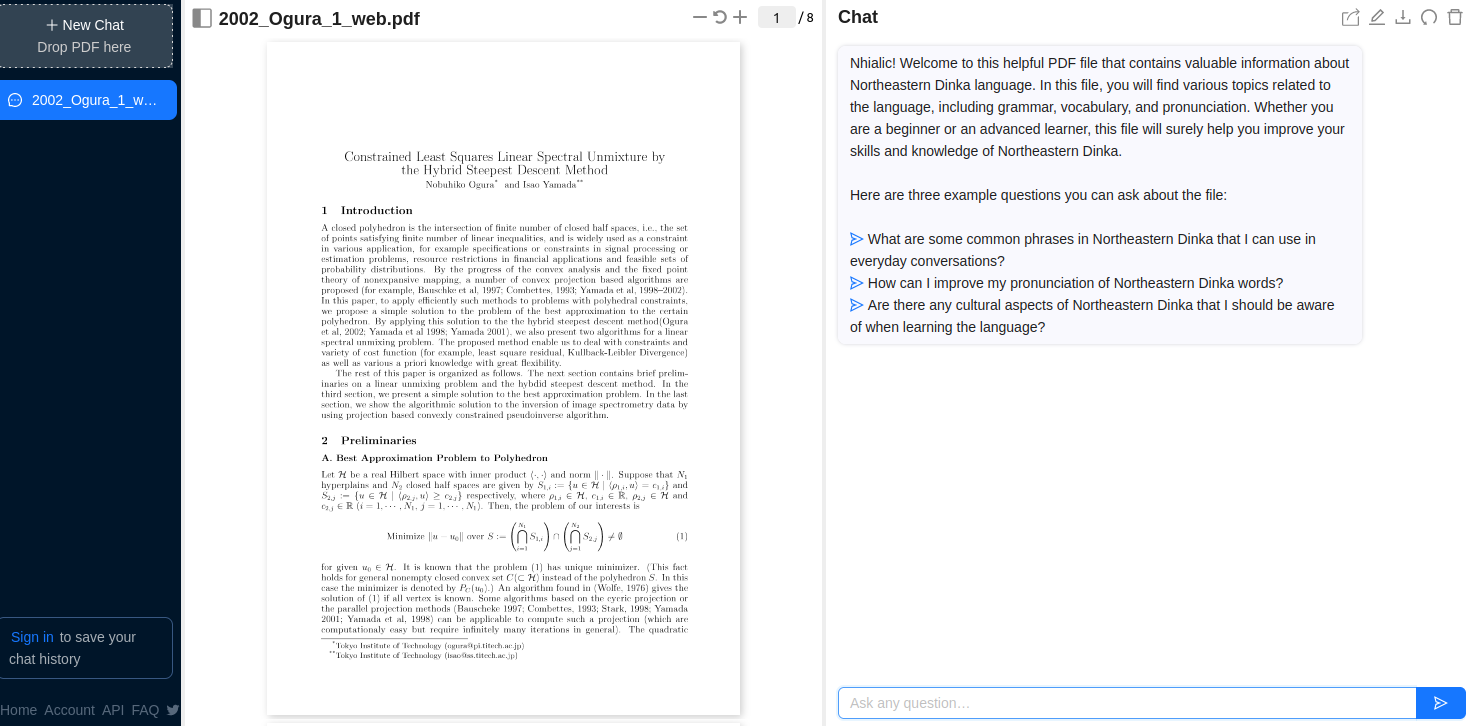
Andy Stapleton gets exasperated waiting for AI tools to answer questions about academic research. But the real culprit isn't ChatGPT, it's the PDFs he feeds to the tools, which are a horror to parse. Gotta admit I didn't realize this upside to the inscrutability of PDFs: they resist being harvested by AI 🤷”
Tim Allison noticed ChatGPT's confusion:
This is a broken PDF...one of my favorites. The extracted text is 100% junk...not in fact a comprehensive guide to the Northeastern Dinka language.
TAKEAWAY: AI cannot do a good job if the PDF makes accurate text extraction difficult, if text recognition / OCR results are of low quality, or the AI software doesn’t perform basic quality checks.
RIP Bram Moolenaar, creator of VIM - a PDF-aware editor
The creator of VIM, one of the most powerful free open-source editors that also pioneered the concept of “charityware” recently passed away. A little known fact is that VIM (for “Vi IMproved”) supports colored PDF syntax highlighting via a special VIM syntax file typically installed at /usr/share/vim/vimXX/syntax/pdf.vim. In addition, VIM plugins support automatic text extraction from PDFs.
PDFacademicBot for August, 2023
Panda, S. (2023) ‘Enhancing PDF interaction for a more engaging user experience in library: Introducing ChatPDF’, IP Indian Journal of Library Science and Information Technology, 8, pp. 20–25. Available at: https://doi.org/10.18231/j.ijlsit.2023.004.
Fayyaz, N., Khusro, S., and Imranuddin (2023) ‘Enhancing Accessibility for the Blind and Visually Impaired: Presenting Semantic Information in PDF Tables’, Journal of King Saud University - Computer and Information Sciences, p. 101617. Available at: https://doi.org/10.1016/j.jksuci.2023.101617.
Bassinet, A. et al. (2023) ‘Large-scale Machine-Learning analysis of scientific PDF for monitoring the production and the openness of research data and software in France’, HAL Open Science, p. 59. Available at: https://hal.science/hal-04121339v2.
Zhang, R. et al. (2023) ‘Knowledge Graph Construction from Tables in Chinese Electric Power PDF Documents’, in Proceedings of the 2023 4th International Conference on Computing, Networks and Internet of Things. New York, NY, USA: Association for Computing Machinery (CNIOT ’23), pp. 525–530. Available at: https://doi.org/10.1145/3603781.3603873.
Gauquier, A. and Senellart, P. (2023) ‘Automatically Inferring the Document Class of a Scientific Article’, in Proceedings of the ACM Symposium on Document Engineering 2023. New York, NY, USA: Association for Computing Machinery (DocEng ’23), pp. 1–10. Available at: https://doi.org/10.1145/3573128.3604894.
