


Deriving HTML from PDF: an algorithm
PDF Association newsJune 15, 2019

PDF Association newsJune 15, 2019

About Roman Toda, Foxit Corporation
For the two most common web formats – HTML and PDF – the relationship hasn’t been easy.
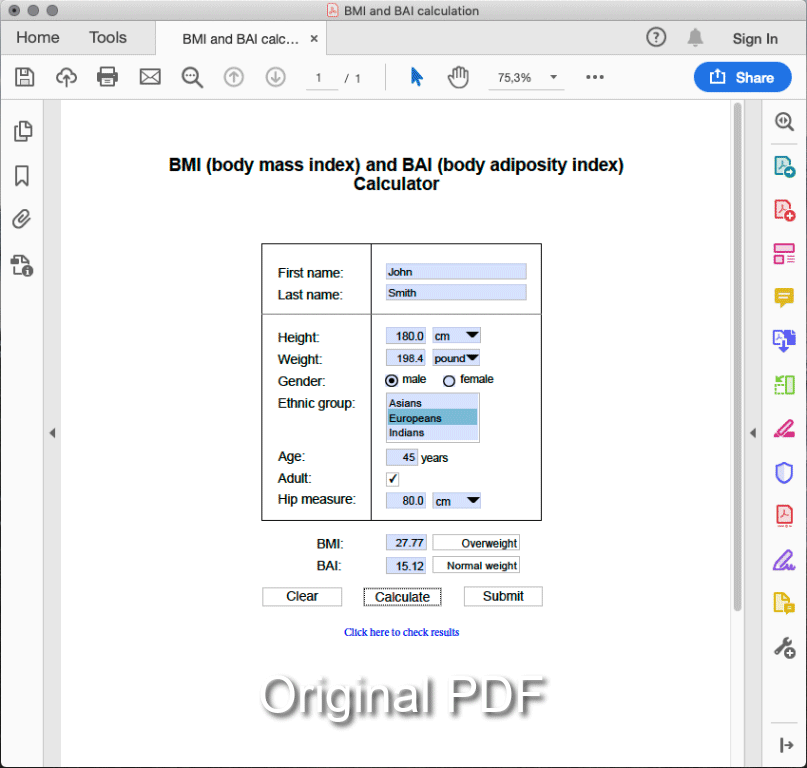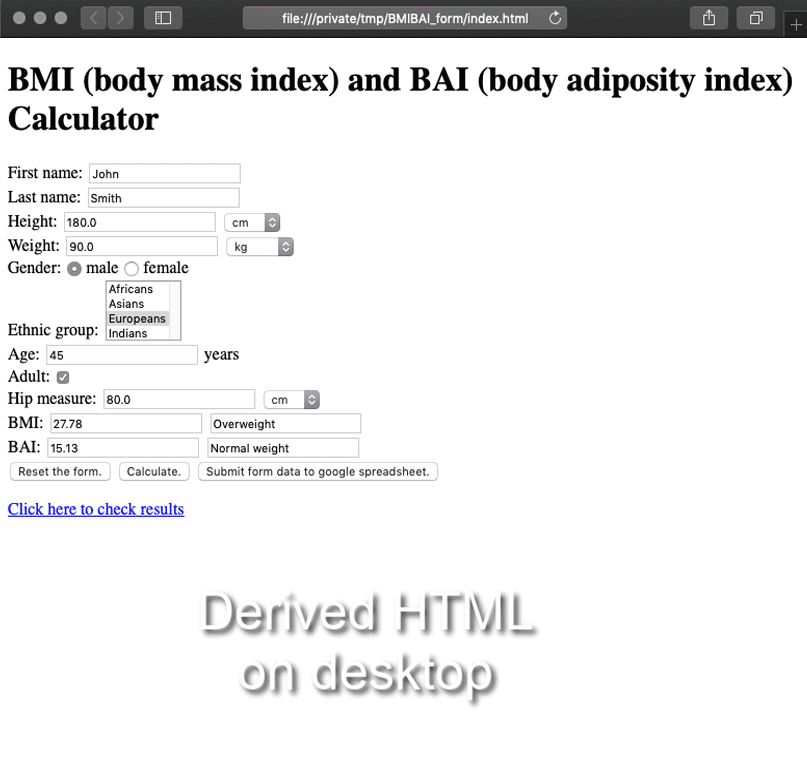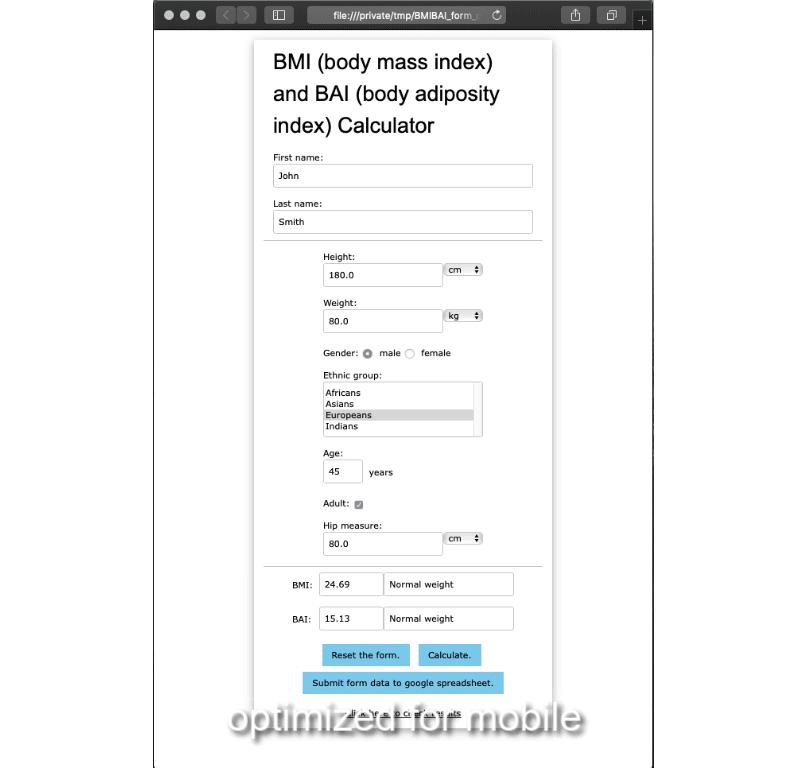 Whenever PDF is used on a website it’s usually in the form of a download link. Rarely, the end user sees some sort of abstract or short description before leaving the website for some sort of PDF viewer.
Whenever PDF is used on a website it’s usually in the form of a download link. Rarely, the end user sees some sort of abstract or short description before leaving the website for some sort of PDF viewer.
For interactive forms, navigation, responsiveness, content reflow, data interchange, dynamic view and accessibility, both formats use their own techniques to achieve user’s goals. Web developers decide which platform to use everything else proceeds from that choice.
Authors see PDF as an end format; this concept doesn’t fit with characteristic ideas about websites where HTML developers decide how the data are presented. But what if you are the author? Can you decide how your pdfs are consumed on the web?
The PDF Association recognizes these pains. A few years ago the organization formed a technical working group to develop proposals and solutions. The objective is to help users with less PDF knowledge overcome difficulties with integration of PDF files into web-based workflows.
Today we are announcing version 1.0 of our specification: “Deriving HTML from PDF”. The document describes the process of producing conforming HTML from a tagged PDF. Developed under PDF Association auspices in a consensus-based process available to all members, we recognize the future of PDF in embedding structure and enrich it with new PDF 2.0 features like the new PDF 2.0 tagset, associated files, namespaces and more. Without compromising traditional PDF’s value proposition as a fixed-layout content we show that well-tagged PDFs can be reliably reused in the HTML context.
With this “derivation algorithm” we provide authors with powerful reasons to create reusable content in PDF, and developers algorithms to unambiguously consume such content so we all can benefit from coexistence of PDF and HTML in years to come.
