


Introducing iText pdf2Data 4.0: Template management and much more!
Member NewsDecember 15, 2022

Member NewsDecember 15, 2022
About iText
The views expressed in this article are those of the author(s) and do not reflect the policies or positions of the PDF Association.
Introduction
We’re pleased to announce a new release of iText pdf2Data; our user-friendly template-based data extraction solution. We’ve been hard at work since the previous release, and as promised last time there’s a wealth of new stuff to tell you about. Think of it as an early Christmas present from us 😊.
The biggest change is the introduction of the pdf2Data Manager. This is a new component to manage your extraction templates more easily, create and manage users and workspaces, and more besides. We’ve also improved the template creation and data field editing experience to accelerate and support collaboration in document workflows.
As this is a major release, we’ve also taken the opportunity to revise the pdf2Data SDK’s API to make it clearer and more consistent, with some other additions and improvements mixed in.
Since these are some pretty significant additions and improvements to iText pdf2Data, we’re also bumping the version number to 4.0. Let’s get right into it.
What's new
pdf2Data Manager
If you’re familiar with iText DITO, our other user-friendly PDF document solution, then you’ll recognize a lot of similarities with the new pdf2Data Manager. Like iText DITO’s management component, it serves as the central environment for iText pdf2Data. All users must now log in with their credentials to help protect your data and prevent unauthorized access. They are then presented with a clear and user-friendly interface where they can access, import, and export extraction templates.
Since we want to ensure a seamless transition between management and editing, it is tightly integrated with the pdf2Data Editor where you define the data fields and parsing rules in your templates. Once you are done editing, you simply save and exit back to the Manager screen.
The pdf2Data Manager acts not only as a centralized storage for all your extraction templates but also allows the administration of users and multiple workspaces. Administrators can easily create and manage users and user roles, and also assign them to specific workspaces.
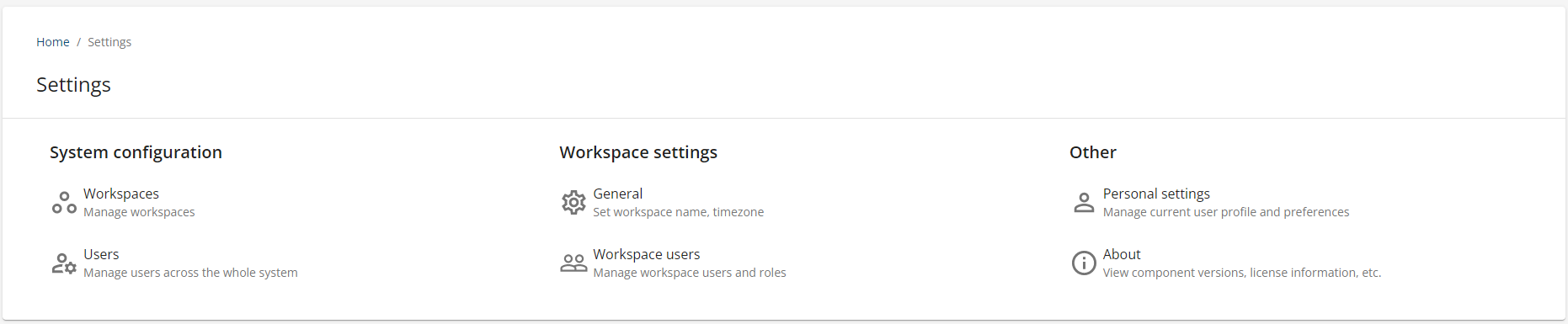
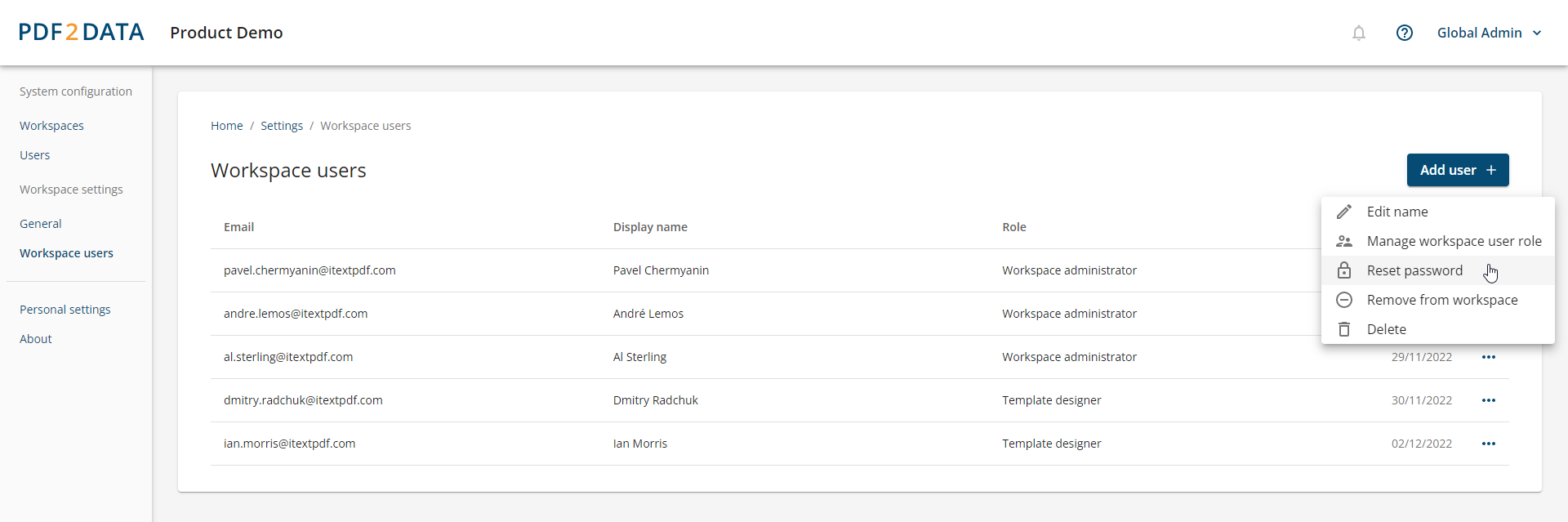
By selecting a particular template in the pdf2Data Manager you can also adjust existing parsing rules for templates, and quickly replace the reference PDFs used to verify extraction templates.
Finally, it’s now even easier to get started with iText pdf2Data with the introduction of template blueprints for extracting data from specific document types. Blueprints can reduce time when creating extraction templates, since they have predefined data fields which you can adapt for your own documents by simply replacing the sample file and adjusting the existing fields. In this release we have included an invoice blueprint, although we’ll be building more blueprints soon.
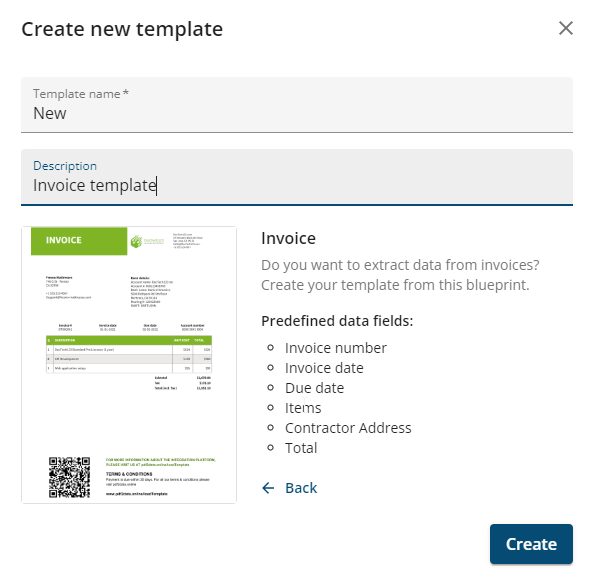
To allow iText pdf2Data to support all this new functionality, we are moving to a new more flexible and reusable format for extraction templates. Don’t worry though; you won’t need to recreate your existing templates since the pdf2Data Manager includes a tool to import and convert your legacy templates into the new format.
pdf2Data Editor
As noted, the new pdf2Data Manager is integrated with the existing pdf2Data Editor so you can seamlessly switch between template editing and management. For this version though, we’ve made some improvements to the user experience when editing templates and data fields. While in earlier versions, you sometimes needed to use the expert mode to get the most out of it iText pdf2Data, that is no longer the case.
From now on, all extraction functionality is entirely available from the UI, although fans of the expert mode will be happy to know it still exists. Expert mode users now also get the benefit of a new and more convenient syntax.
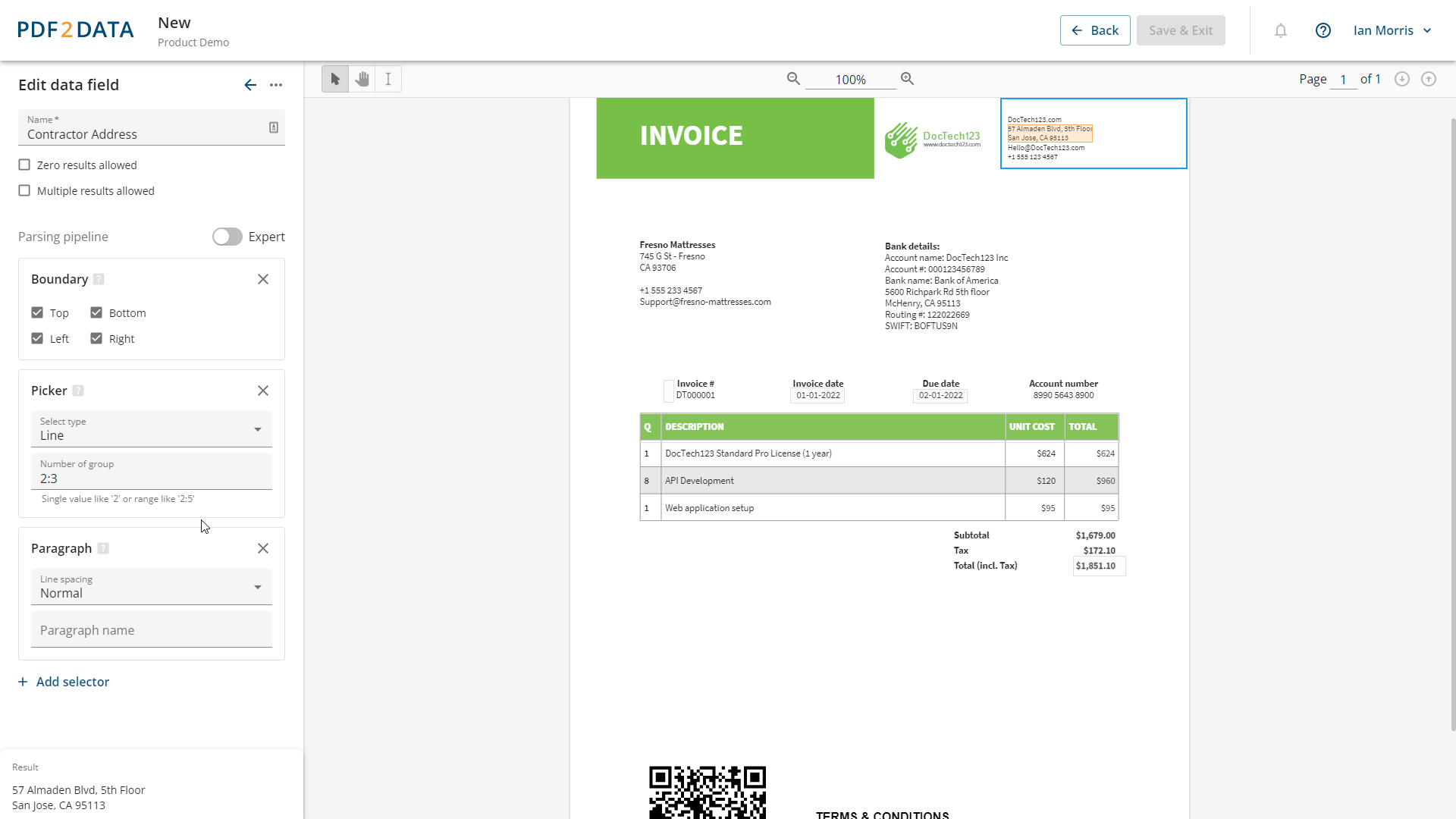
pdf2Data SDK
The SDK is the key part of iText pdf2Data that manages the job of document data extraction. While template designers are won’t ever have to deal with the SDK itself, developers will be happy to know we’ve made some improvements to its API. This will mean they can read less documentation in order to integrate it into workflows. And of course, it has been updated to fully support the new template format.
Extraction updates
On top of its high-volume PDF data extraction capabilities, our built-in extraction algorithms are what makes iText pdf2Data special. These are fine-tuned to recognize common document elements such as tables, paragraphs, dates, and so on. We are adding to and improving these all the time, and this release is no exception.
Table extraction gained improved merging strategies, specifically for tables which span multiple pages. Error messages became clearer, so more useful for debugging. In addition, the overall extraction process became more stable, reducing the chance of exceptions leading to problems.
Want to know more?
As usual, you can find all the technical details in the release notes on our Knowledge Base, along with our revised installation guides and other documentation. If you’re not already an iText pdf2Data customer, you can request a free 30-day online trial to test it out for yourself, or check the product page to learn more about its data extraction capabilities.
If you are interested in learning more or have additional questions.
Original post: https://itextpdf.com/blog/itext-news-technical-notes/introducing-itext-pdf2data-40-template-management-and-much-more
The iText Suite is a comprehensive PDF SDK which includes iText Core and optional add-ons to give you the flexibility to fit your needs. iText Core is an open source PDF library that you can build into your own applications and is a re-imagining of the popular iText 5 engine…
Read more