


Jpegli works in PDF
ArticleFebruary 23, 2025

ArticleFebruary 23, 2025

About Peter Wyatt, PDF Association
Jpegli is a relatively new open-source JPEG library created by Google. It’s backward compatible with existing JPEG while improving its compression ratio by 35%. Jpegli uses concepts from JPEG XL, which the PDF Association’s Imaging Model TWG is separately considering for future adoption into PDF to support HDR and wide color gamut images.
With Jpegli, reduced-size 2D images are stored using the DCTDecode filter that was introduced with PDF 1.0 and is in every PDF implementation today.
BUSINESS NOTE
Google’s Jpegli promises smaller JPEG images (and so, smaller PDF files) with no change to reader software!
BUSINESS NOTE
Google’s Jpegli promises smaller JPEG images (and so, smaller PDF files) with no change to reader software!
A quick assessment
Although Google’s researchers provide extensive details on their image quality assessment of Jpegli, including publishing a paper titled “Users prefer Jpegli over same-sized libjpeg-turbo or MozJPEG”, their focus was on web content – specifically, achievable image quality for a fixed transmission size.
Lossless images in PDF almost exclusively use FLATE compression (FlateDecode filter), with JPEG compression (DCTDecode filter) reserved for lossy images, where blocky artifacts may appear on certain devices. For PDF the main benefit will be replacing existing JPEG images with smaller equivalents compressed using Jpegli without impacting the many thousands of PDF viewers, renderers, and applications that exist today. Following the instructions in Google’s GitHub Jpegli repository, we built the Linux version of the command line utility cjpegli that can recompress various types of image formats:
$ git clone https://github.com/google/jpegli.git
$ cd jpegli
$ git submodule update --init --recursive
$ ./ci.sh release
$ ./build/tools/cjpegli --help -v
Usage: ./build/tools/cjpegli INPUT OUTPUT [OPTIONS...] INPUT
the input can be JXL, PPM, PNM, PFM, PAM, PGX, PNG, APNG, GIF, JPEG, EXR
OUTPUT
the compressed JPEG output file
--disable_output
No output file will be written (for benchmarking)
-x key=value, --dec-hints=key=value
color_space indicates the ColorEncoding, see Description();
icc_pathname refers to a binary file containing an ICC profile.
-d maxError, --distance=maxError
Max. butteraugli distance, lower = higher quality.
1.0 = visually lossless (default).
Recommended range: 0.5 .. 3.0. Allowed range: 0.0 ... 25.0.
Mutually exclusive with --quality and --target_size.
-q QUALITY, --quality=QUALITY
Quality setting (is remapped to --distance). Default is quality 90.
Quality values roughly match libjpeg quality.
Recommended range: 68 .. 96. Allowed range: 1 .. 100.
Mutually exclusive with --distance and --target_size.
--chroma_subsampling=444|440|422|420
Chroma subsampling setting.
-p N, --progressive_level=N
Progressive level setting. Range: 0 .. 2.
Default: 2. Higher number is more scans, 0 means sequential.
--xyb
Convert to XYB colorspace
--std_quant
Use quantization tables based on Annex K of the JPEG standard.
--noadaptive_quantization
Disable adaptive quantization.
--fixed_code
Disable Huffman code optimization. Must be used together with -p 0.
--target_size=N
If non-zero, set target size in bytes. This is useful for image
quality comparisons, but makes encoding speed up to 20x slower.
Mutually exclusive with --distance and --quality.
--num_reps=N
How many times to compress. (For benchmarking).
--quiet
Suppress informative output
-v, --verbose
Verbose output; can be repeated, also applies to help (!).
-h, --help
Prints this help message. All options are shown above.
We then took a very small sample of different classes of content that typically use JPEG in PDF and recompressed these images using cjpegli ‘s default options (equivalent to --quality=90):
| Content type | Filename | Width (pixels) | Height (pixels) | Original JPEG (bytes) | Jpegli compressed (bytes) | Saving (%) |
| Synthetic image | EasterEgg.jpg | 1331 | 885 | 509,571 | 154,481 | 70% |
| Edited photo (no ICC profile) | GT6Mk1.jpg | 1920 | 1440 | 765,957 | 874,434 | -14% |
| iPhone Photo with ICC profile | IMG_5675.jpg | 6368 | 3142 | 5,575,212 | 3,254,206 | 42% |
| iPhone Photo with ICC profile | IMG_5677.jpg | 3494 | 2512 | 1,753,384 | 977,842 | 44% |
| Collage of screenshots | LinkAnnot-appearances.jpg | 2546 | 1394 | 672,007 | 334,986 | 50% |
| Average saving: | 38% |
Each of these Jpegli-compressed images was then manually encapsulated into a single-page PDF file in which the image was the only content. The DCTDecode stream Length entry exactly matches the Jpegli-compressed size as shown in the table above.
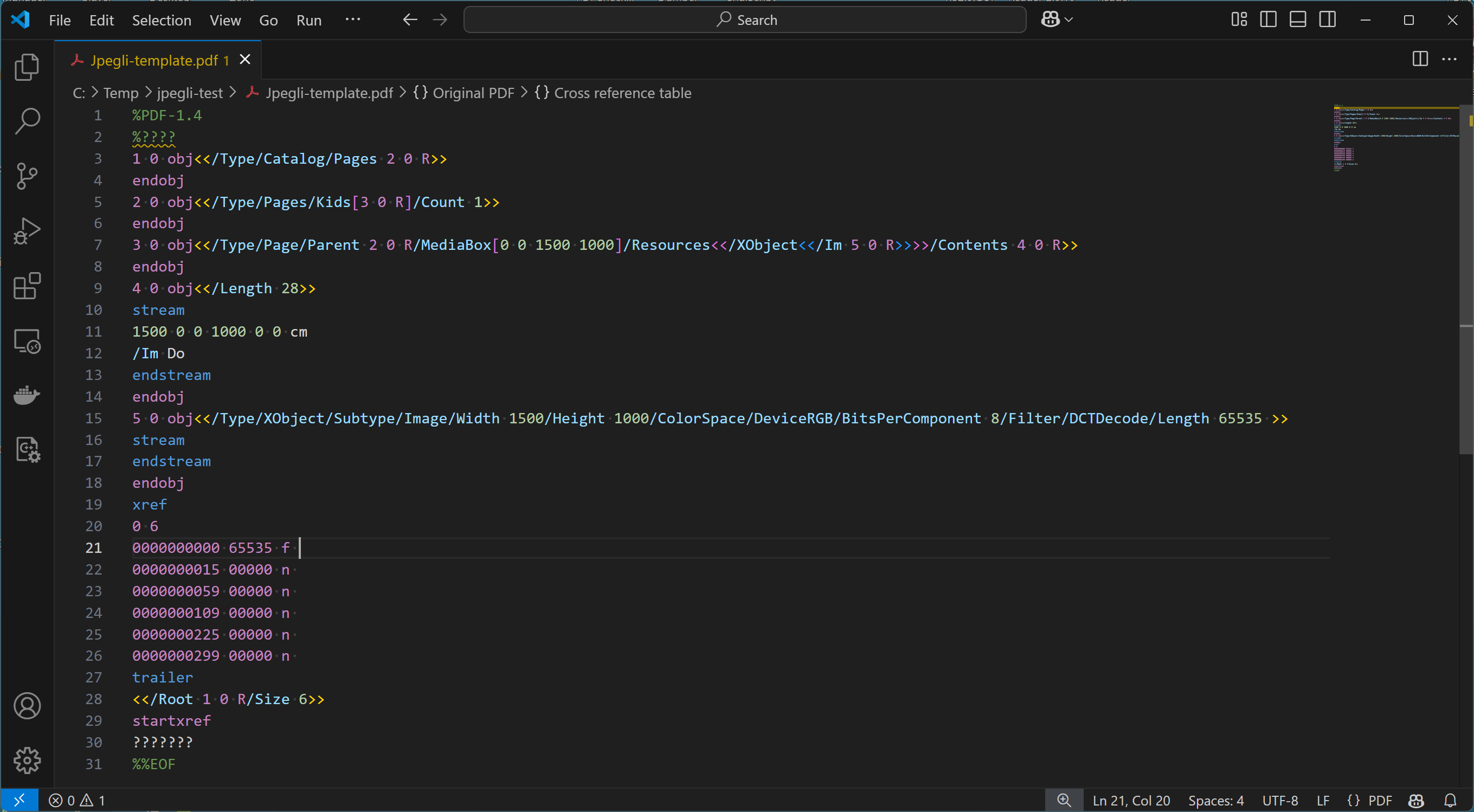
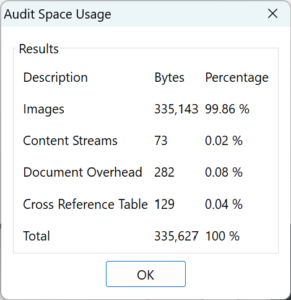 The PDF syntax adds a very small overhead of approximately (due to the differing number of digits in the width and height of each image) 640 bytes to the size of the Jpegli-compressed image, so 99.95% of the bytes constituting these PDFs are the image data. Any issues with these PDFs will thus most likely be related to the image data.
The PDF syntax adds a very small overhead of approximately (due to the differing number of digits in the width and height of each image) 640 bytes to the size of the Jpegli-compressed image, so 99.95% of the bytes constituting these PDFs are the image data. Any issues with these PDFs will thus most likely be related to the image data.
These PDFs were then opened and viewed without issue in over 50 commercial and open-source PDF applications on PC, Mac, and Linux platforms. By checking application and licensing documentation, we confirmed that various JPEG decoding libraries successfully processed these Jpegli-compressed images. We also noticed no compression artifacts on-screen. We did not assess rendering performance.
Conclusion
Although our experiments were not comprehensive, our results confirm Google’s claim of a 35% size saving across most (but importantly not all!) JPEGs, as well as demonstrated backward compatibility with existing JPEG decoders. Very significantly, no existing PDF implementation we tested had any issues processing Jpegli image data.
If you write PDF creation software and need to minimize file size, consider adding Google’s Jpegli library. It allows you to squeeze even more out of PDF’s current DCTDecode filter without impacting image quality or PDF interoperability with existing technology. The more JPEGs in a PDF document, the bigger the saving potential.
Adapting the conclusion of the Google researchers: Jpegli is a promising new technology that has the potential to make the internet PDF faster and more beautiful smaller.
Try it for yourself!
 Download example files: Here's an original JPEG, the jpegli version, and a PDF containing the jpegli image.
Download example files: Here's an original JPEG, the jpegli version, and a PDF containing the jpegli image.
{kind=link}
