


PDF malformations and more
PDF in the WildSeptember 6, 2023
PDF in the WildSeptember 6, 2023
About PDF Association staff
Funky PDF != malformed PDF
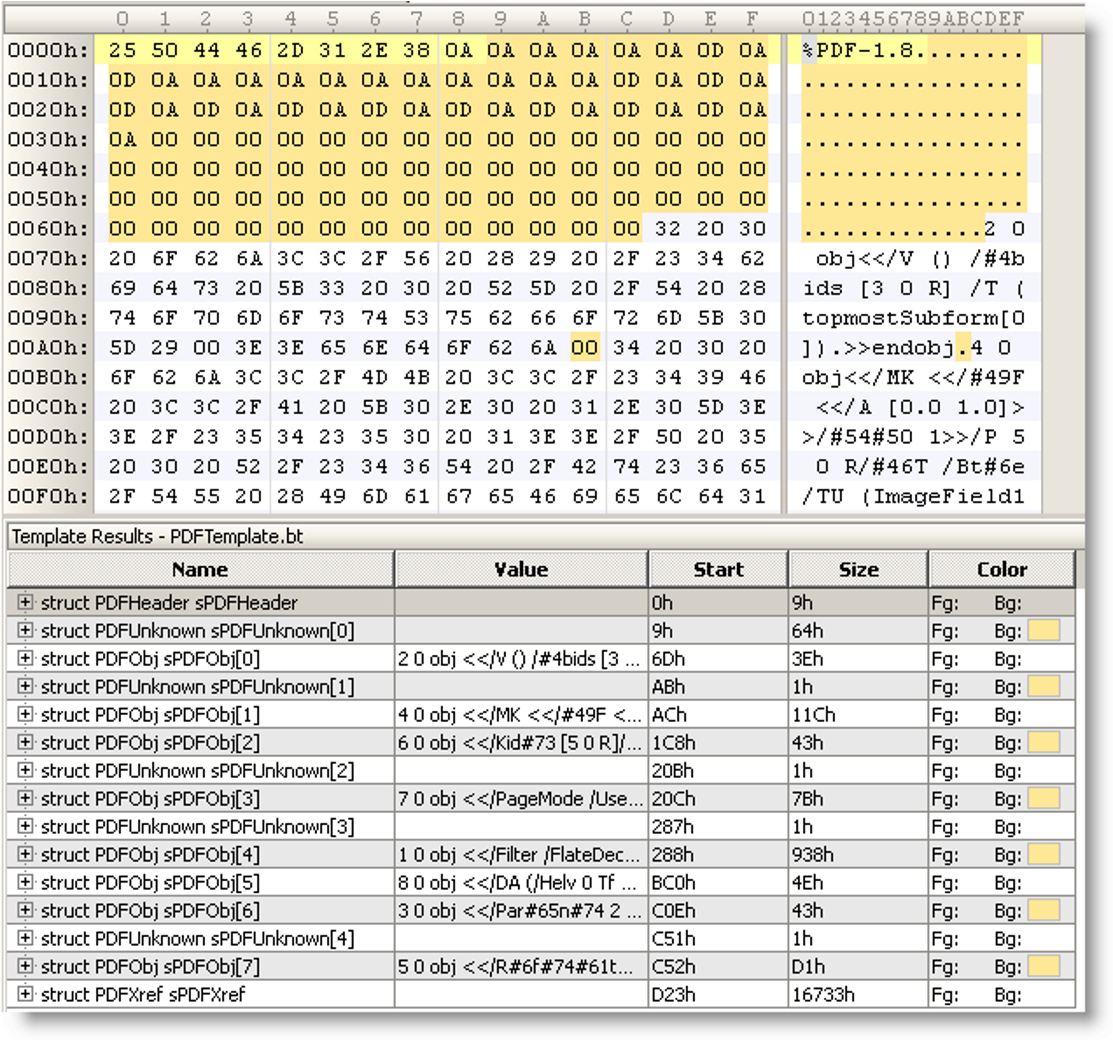
The image posted in this tweet caught our attention. When we traced through to the source it was captioned as “It’s particularly useful for malformed PDF files, like this example with PDFUnknown structures”.
But is this PDF really malformed? Is that yellow or orange highlight supposed to be the malforms?

Obviously PDF version 1.8 is unexpected (as no specification of that name has ever existed!), but the file is otherwise entirely syntactically valid. Back in 2008, when this was first posted, no one knew that PDF 1.8 would never exist. All PDF software should handle files “from the future” with unexpected version numbers.
If we then examine the orange highlighted bytes, including the single byte at offset 00ABh, there are a lot of NULs (00). Unlike many programming languages, PDF has explicitly included NUL (00) as a valid whitespace character since PDF 1.3 back in 2000 - see Table 1 in ISO 32000. These NULs are valid!
If we look at the objects (object 2 and part of object 4) we can see several name objects including 2-digit hexadecimal escape sequences starting with a NUMBER SIGN (23h) (#). This construct is as described in ISO 32000, 7.3.5, and is also entirely valid since PDF 1.2 in 1996.
If we normalize these objects and arrange them nicely we get:
2 0 obj
<<
/V ()
/Kids [3 0 R]
/T (topmost.Subform[0])
>>
endobj
4 0 obj
<<
/MK <<
/IF <<
/A [ 0.0 0.1 ]
>>
/TP 1
>>
/P 5 0 R
/FT /Btn
/Tu (ImageField1
So the remaining question is are these two lexically valid objects also semantically valid or meaningful? What kinds of dictionaries are these very out-of-context objects? Where is this malform??
Object 2 has V and T entries, both strings, and an array in the Kids entry. A simple grep command for V keys that are strings (grep -P “^V\t.*string” *) against the Arlington PDF Model gives only 4 possibilities, while the same command for T gives 32 possibilities reducing the possibilities to just 2 variants of field objects: FieldChoice or FieldTx. We can thus easily conclude that object 2 is a valid Field dictionary (on the assumption that the required DA key is inherited).
We can only see part of object 4 in the screenshot, but we know it has at least MK, P,FT and TU entries, and that the MK inline dictionary has an IF dictionary and TP number entries. Armed with this knowledge we can query the Arlington PDF Model again, revealing that object 4 must be a screen or widget annotation, the MK entry is an Appearance Characteristics dictionary, and the IF entry is an Icon Fit dictionary. All are perfectly valid.
So, the screenshot does not indicate any malforms. Things might be a bit unusual (such as PDF 1.8 and the seriously unnecessary use of 2-digit hex codes for standardized key names) but that’s it. This sort of obfuscation of standardized features (key names using partial 2-digit hex codes) is a common tactic of malicious attackers who try to bypass anti-malware software, but it is not invalid PDF.
Rather, we are simply looking at an indication that some anti-malware solutions can be easily tricked - and that their developers have not read (or understood) PDF’s specification.
The tool behind the screenshot is the 010 Editor by SweetScape Software which is widely used by cyber-security researchers and digital file forensic experts. As a result of our observation, the PDF Association, acting on behalf of industry and end-users, reported a fix to the parsing error causing the erroneous syntax highlighting. The root cause was that 2 of the 6 PDF whitespace characters were not supported. This fix was accepted and is now available as a free download.
JPCERT/CC discovers “MalDoc in PDF”
The Japan Computer Emergency Response Team Coordination Center (JPCERT/CC) reported a new cyber threat on August 28 which they have dubbed “MalDoc in PDF, including a video of the malware in action. This threat bypasses detection by embedding a malicious Word file into a partial PDF file.

As can be seen in this screenshot from JPCERT/CC, the start of the malware (which has a “.doc” file extension) appears as a valid PDF file, but after some bytes we can see the malicious MIME payload (a Word document with macros) appear.
This technique is sometimes referred to as a “polyglot”, as different applications may detect the file type in various ways. In this case the partial PDF portion is clearly not a fully valid PDF. One application (that examines the initial bytes) may decide this is a PDF file while another (that relies on the file extension) may think it is a Word document.
Can you spot the first error in the PDF portion of this malware?
It is not at offset 0C17 as shown in green highlight, but at 0BFD where the bytes “r12” are the value of the key “P=” in the Properties dictionary. “r12” is not valid syntax for a PDF object.
“Poison PDFs” targeting children
Cyber-security researcher Zak Edwards has revealed cyber-safety threats to children from hackers using “poison PDFs”:
“Vulnerabilities or weaknesses in a website's backend, or its content management system, are exploited by attackers who upload malicious PDF files to the website. These documents, which Edwards calls “poison PDFs,” are designed to show up in search engines and promote “free Fortnite skins,” generators for Roblox’s in-game currency, or cheap streams of Barbie, Oppenheimer, and other popular films. The files are packed with words people may search for on these subjects.
When someone clicks the links in the poison PDFs, they can be pushed through multiple websites, which ultimately direct them to scam landing pages, says Edwards, who presented the findings at the August, 2023 Black Hat security conference in Las Vegas. There are “lots of landing pages that appear super targeted to children,” he says.”
6,857 PDFs bringing order to LEGO
Gizmodo reports that it’s finally possible to locate that missing LEGO instruction manual and convert that pile of LEGO bricks into the intended design. According to the description on the site, the Internet Archive’s new LEGO Building Instructions collection contains “a dump of all available building instruction booklet PDFs from the LEGO website” as of March 2023. The collection totals 6,857 PDFs and a whopping 481.7 GB!
NASA does PDF?
Who knew that NASA researches PDF as well?
Future InkScape 1.4 working on PDF/X and CMYK color management
Open source software developer Martin Owens discusses the development goals and challenges for the upcoming release of InkScape 1.4, including multiple kinds of PDF/X output with full CMYK color management: “What’s next for InkScape? Developer Update, 5th August 2023“ (from 6:49” → 9:15”).

PDFacademicBot for September, 2023
Song, E. et al. (2023) ‘Double-Layer Detection Model of Malicious PDF Documents Based on Entropy Method with Multiple Features’, Entropy, 25(7), p. 1099. Available at: https://doi.org/10.3390/e25071099.
Stivala, G. et al. (2023) ‘A Large-Scale Study of Phishing PDF Documents’. arXiv. Available at: http://arxiv.org/abs/2308.01273.
Liu, R., Matuszek, C. and Nicholas, C. (2023) ‘A PDF Malware Detection Method Using Extremely Small Training Sample Size’, in Proceedings of the ACM Symposium on Document Engineering 2023. New York, NY, USA: Association for Computing Machinery (DocEng ’23), pp. 1–4. Available at: https://doi.org/10.1145/3573128.3609352.
Krpachovska, M. and Mirceva, G. (2023) ‘Processing PDF Documents Written in Macedonian Language Using UiPath Document Understanding’, 20th International Conference on Informatics and Information Technologies [Preprint].
Pathirana, P. et al. (2023) ‘A Comparative Evaluation of PDF-to-HTML Conversion Tools’, in 2023 International Research Conference on Smart Computing and Systems Engineering (SCSE), pp. 1–7. Available at: https://doi.org/10.1109/SCSE59836.2023.10214989.
Khan, B., Arshad, M. and Shah Khan, S. (2023) ‘Comparative Analysis of Machine Learning Models for PDF Malware Detection: Evaluating Different Training and Testing Criteria’, Journal of Cyber Security, 5(0), pp. 1–11. Available at: https://doi.org/10.32604/jcs.2023.042501.
Nancy Thomas and Daniel Borrajo (2023) ‘Tree-Based Structural Representation and Difference Computation for PDF Documents’. USA: Research Square. Preprint. Available at: https://doi.org/10.21203/rs.3.rs-3266947/v1.
