

The PDF Association is a DARPA success story
PDF in the WildOctober 12, 2023

PDF in the WildOctober 12, 2023
About PDF Association staff
“Our biggest success-story is our interaction with the PDF Association”
So said Dr. Sergey Bratus, Program Manager for DARPA’s SafeDocs fundamental research program, in a recent interview on the Security Conversations podcast (starting at 13:30). Dr. Bratus goes on to describe the purpose and capabilities of the Arlington PDF Model, developed by the PDF Association during its performance on SafeDocs.
“How intellectually lazy can an author be”?
“How intellectually lazy can an author be?’ the PDF format leads to a loss of semantic information
People can read PDFs and learn all the information in their rendered pages.
An "AI researcher" inability to extract this information tells us more about the researcher than it does about rendering text on a page, which PDFs do well.”
That's according to software development manager Peter Williams, who exposes yet another example of why the PDF Association offers a free peer review service for academics working with PDF files!
Researchers should know that not only does our Deriving HTML from PDF Technical Working Group define advanced algorithms for reliable conversion of PDF to HTML, but they and the LaTeX Project Liaison Working Group provide guidance to authors on methods to ensure rich and reliable information transformation.
If you are researching (or reading research on) PDF, you should check with us before referencing old technology of dubious provenance.
Coherently navigating PDF “hex dumps”
Last month’s “PDF in the Wild” reported on a commercial tool widely used by the digital forensics community and cybersecurity researchers. This tool is an advanced binary editor that provides viewing and editing of the byte values that make up digital files. In addition, scripts (so called “binary templates”) can be used to structure and highlight ranges of bytes in what is otherwise an overwhelming hex dump. One advantage of such a low level view is that the specific byte values and sequences can be observed precisely as they appear within the PDF file.
SweetScape’s 010 Editor existing support for PDF was developed many years ago by a well known and well respected cybersecurity researcher, but was incorrect according to the PDF specification. As a consequence, numerous cybersecurity researchers were led to erroneously identify problems with PDF files; a bad outcome for all concerned.
Having determined the problem, PDF Association CTO Peter Wyatt rewrote the 010 Editor’s Binary Template for PDF with greater fidelity to PDF’s specified lexical rules. The latest release of PDF.bt (for v14 of 010 Editor) now provides a much richer, more insightful and robust understanding of PDF files using correct PDF terminology, as shown below.
Note that this software does not offer a full semantic parse as per the PDF specification, but provides a simple means of highlighting byte ranges of high-level PDF file sections and objects based on specific PDF keywords and associated lexical rules (such as the body section, conventional cross reference tables, trailer, etc.). This capability is exceptionally useful when examining malicious, malformed, or corrupted PDF files - and when detailed knowledge of PDF syntax is vital.
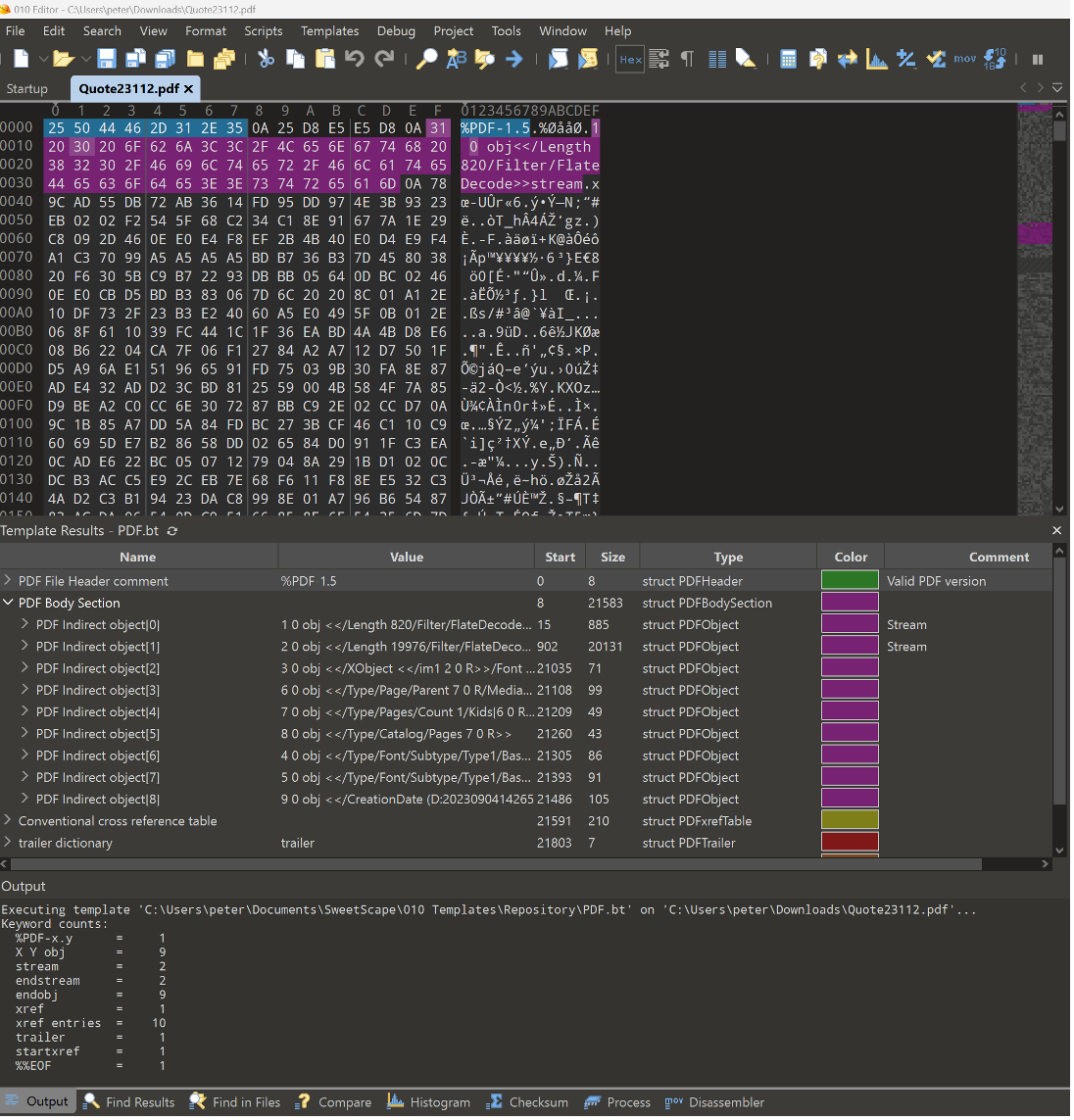
When coupled with an update to the script BracketMatching.1sc it is now also possible to navigate a PDF file at a PDF object level. Bracket matching allows quick navigation between the starting and ending tokens for PDF dictionaries (<<… >>), arrays ([ … ]), literal strings (( … )) and hex strings (< … >), so that complex nested sequences of direct PDF objects can be more rapidly traversed.
Other specialized PDF applications, such as iText RUPS, Apache PDFBox Debugger, QPDF’s “qdf” or JSON output modes, MuPDF’s mutool clean utility, etc. can be used to view or better understand semantically parsed PDF objects when processed according to the PDF specification, such as by examining the document object model (DOM) with specific dictionary keys and values. However, when these tools fail to process a PDF, or process it in unusual or varying ways, it is not always obvious as to the cause - this is when a binary editor is most useful.
Google advances document understanding with an open data set
“The last few years have seen rapid progress in systems that can automatically process complex business documents and turn them into structured objects. A system that can automatically extract data from documents, e.g., receipts, insurance quotes, and financial statements, has the potential to dramatically improve the efficiency of business workflows by avoiding error-prone, manual work. Recent models, based on the Transformer architecture, have shown impressive gains in accuracy. Larger models, such as PaLM 2, are also being leveraged to further streamline these business workflows. However, the datasets used in academic literature fail to capture the challenges seen in real-world use cases. Consequently, academic benchmarks report strong model accuracy, but these same models do poorly when used for complex real-world applications.
In “VRDU: A Benchmark for Visually-rich Document Understanding”, presented at KDD 2023, we announce the release of the new Visually Rich Document Understanding (VRDU) dataset that aims to bridge this gap and help researchers better track progress on document understanding tasks. We list five requirements for a good document understanding benchmark, based on the kinds of real-world documents for which document understanding models are frequently used. Then, we describe how most datasets currently used by the research community fail to meet one or more of these requirements, while VRDU meets all of them. We are excited to announce the public release of the VRDU dataset and evaluation code under a Creative Commons license.”
Read more on Google’s blog.
PDFacademicBot for October, 2023
Lam, D., Li, L. and Anderson, C. (2023) PDF investigation with parser differentials and ontology. preprint. Available at:https://doi.org/10.36227/techrxiv.23290277.v1.
Satria, H. and Primanita, A. (2023) ‘Automatic Data Extraction Utilizing Structural Similarity from A Set of Portable Document Format (PDF) Files’, Sriwijaya Journal of Informatic and Applications, 4(2), p. pp.36-47. Available at:http://sjia.ejournal.unsri.ac.id/index.php/sjia/article/viewFile/89/39.
Beth Richard (2023) ‘Key Issues Affecting the Inclusion of Alt Text in Scholarly PDF Publications’, Logos, 34(1), pp. 44–60. See: https://doi.org/10.1163/18784712-03104058.
Konstantin Nikolaev and Olga Nevzorova (2023) ‘Annotation of mathematical formulas in PDF documents’, in. ITNT-2023, Russia: SAMARA NATIONAL RESEARCH INSTITUTE UNIVERSITY NAMED AFTER ACADEMICIAN S.P. KOROLEV, p. pp.54-56. Available at: http://itnt-conf.org/images/docs/2023/index/local/ITNT-2023_5.pdf#page=54.
Blecher, L. et al. (2023) ‘Nougat: Neural Optical Understanding for Academic Documents’. arXiv. Available at:https://doi.org/10.48550/arXiv.2308.13418.
Jordy Mehciz (2023) Integrating digital accessibility in document creation tools. Universiteit Leiden, Leiden Institute of Advanced Computer Science (LIACS). Thesis. English & Dutch. Available at: https://theses.liacs.nl/pdf/2022-2023-MehcizJ.pdf.
Ramadhan, M.R., Mandala, S. and Yulianto, F.A. (2023) ‘Analysis and Implementation of Digital Signature Algorithm in PDF Document’, in 2023 11th International Conference on Information and Communication Technology (ICoICT). 2023 11th International Conference on Information and Communication Technology (ICoICT), pp. 11–16. Available at:https://doi.org/10.1109/ICoICT58202.2023.10262708.
Yu, S., Liang, H. and Dai, C. (2023) ‘A PDF reader based on SM2 algorithm’, in 2023 IEEE International Conference on Sensors, Electronics and Computer Engineering (ICSECE). 2023 IEEE International Conference on Sensors, Electronics and Computer Engineering (ICSECE), pp. 243–246. Available at:https://doi.org/10.1109/ICSECE58870.2023.10263315.
Akdemir Aktaş, H. et al. (2023) ‘Revisiting anatomical structures of the superior orbital fissure using with interactive 3D-PDF model’, Acta Medica, 54(3), pp. 165–171. Available at: https://doi.org/10.32552/2023.ActaMedica.907.
PDF in the Wild
Read more from the PDF Association's monthly feature!
