

German government standardizes on PDF/UA
PDF in the WildMarch 24, 2026

PDF in the WildMarch 24, 2026
About PDF Association staff
German government standardizes on PDF/UA
The Deutschland Stack relies on open international standards to provide the foundation for digital Germany. For semantic technologies (those that convey meaning), the Stack has chosen to standardize on PDF/UA for final-form digital documents.
ISO/IEC committee starts work on a vocabulary for authenticity
ISO/IEC JTC 1 SC 29 (Coding of audio, picture, multimedia and hypermedia information), the committee responsible for standardizing JPEG technologies, has registered a new project: ISO/IEC CD 26080-1 Information technology — Authenticity for Media — Part 1: Vocabulary
This document provides a series of definitions for the authenticity of media. The definitions related to the authenticity of media assets include general terms, terms related to media forgery, and terms related to media anti-counterfeiting methods.
PDF-related work occurring in ISO TC 171 SC 2 WG 13 (Content provenance) on ISO/CD TS 32008 Authenticity of information — Extensions to Content Credentials for ISO 32000-2 (PDF 2.0) will be sure to align with JTC 1 SC 29’s initiative.

Chrome adds ink (not “annotations”) to PDF pages
As of February 19, the company claims that it now supports “PDF annotations” in Chrome. That’s misleading.
The latest Chrome simply adds page content (highlighter marks, scribbles) to PDF pages; it is NOT leveraging PDF’s native annotations feature. The Chromium browser has supported rendering real PDF annotations for quite a while, via the “3 dot” hamburger menu on the right, where the “Annotations” check menu option is available. Chrome’s new feature is not influenced by this option, since the scribbles are not PDF annotations.
We hope Google will fix its incorrect terminology so that everyone who has used PDF annotations since PDF 1.0 was first introduced in 1993 (!) will not be confused!

The challenge(s) PDF poses for AI
Using the Epstein files as a prompt, The Verge covers the nexus of PDF and AI to focus on how confusing PDF files can be to AI that wants to be spoon-fed with JSON, YAML, Markdown, and other simple text-based formats, yet they go on to admit:
"A further problem that arises from and compounds PDF’s inherent difficulty is that models rarely train on them."
So whose fault is that, for such a ubiquitous, well-specified format with literally trillions of example files?
The article opens by stating that the text in the Epstein files is hard to process and unreliable due to poor OCR … but, as we and many others have reported, making TDM (Text and Data Mining) easy wasn’t DoJ’s intention. They could have released the files as redacted “born digital” files, including the email inboxes, but they chose not to. That’s not a file format issue – that’s politics.
It will be up to legislators to be clear when they write laws requiring the release of information, such as EFTA and FOIA, about how to balance considerations like suitability for AI ingestion and redaction.

LaTeX leader and advocate of math in Tagged PDF honored
Frank Mittelbach has led the development of the LaTeX typesetting system, the de‑facto standard in STEM publishing, since 1990.
Frank is well-known to PDF Association members and the wider technical publishing community thanks to his outstanding contributions in several Working Groups that focus on Tagged PDF, especially the LaTeX Project LWG. Our recent article “Accessible Math in PDF finally” highlighted some of the achievements made by Frank and others via the LaTeX Project LWG.
We are delighted to note that last month Frank was awarded an honorary doctorate by Masaryk University in Brno, Czech Republic, and delivered his lecture, Gutenberg – Knuth – Zapf – Lamport – LaTeX: The evolution of document production and information access, as part of the University’s lecture series.
PDF Differences: “PDF versions” test files now public
Not all PDF software reports PDF version numbers the same way! These test files help developers and end users to identify shortcomings in their file identification feature.
Members are reminded about the members-only PDF Differences Preview repo, where test files remain for 60 days before moving to the public repo.
ICC publishes information on small footprint color profiles
After recent ICC meetings in Japan, the ICC approved publication of a new technical white paper, “ICC White Paper 58: Minimizing profile size”, along with a collection of small footprint ICC color profiles. These compact profiles have been eagerly awaited by various stakeholders seeking to reduce the file sizes of PDF/A and PDF/X files while retaining color accuracy in line with color reproduction standards such as FOGRA.
GWG publishes “how to” for print-ready PDFs from Canva
Canva is a professional-grade online graphic design platform that has been growing in popularity. As such, graphic designers need Canva to export high-quality PDFs to ensure reliable print reproduction. The Ghent Work Group (GWG) has now announced a new User Guide and YouTube video that can help graphic designers achieve this goal:
As Canva becomes more popular among designers, educators, marketers, and small businesses, it is increasingly important to ensure that files created on the platform meet professional production standards.
This new guide offers clear, step-by-step instructions to help users prepare their documents correctly for print and digital distribution. Whether you are new to Canva or already familiar with its features, this practical resource will help you work confidently in today’s diverse design environments and workflows.
Typst supports PDF 2.0 and PDF/A-4
The up-and-coming Typst compiler (OSS) translates Typst markup to PDFs, images, and web pages. It now supports PDF 2.0 (including Tagged PDF), PDF/UA-1, and all versions and conformance levels for PDF/A. We hope that the final steps for PDF/UA-2 output are also not too far away!
It’s bonkers!
On LinkedIn, in ALL CAPS, Shifra Williams points out that:
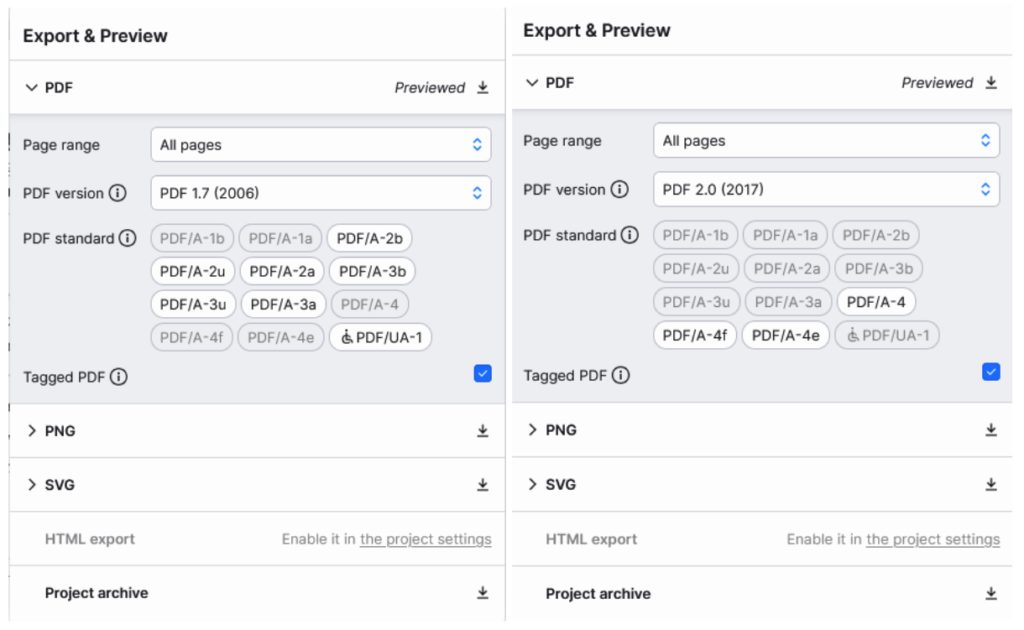
“IT’S BONKERS THAT THE MOST EFFECTIVE WAY TO SAVE SOMETHING AS A PDF IS TO TRICK YOUR COMPUTER INTO THINKING YOU’RE ABOUT TO PRINT IT”
Not all software is so hidebound as to assume that users think about print when they want a PDF, but it’s common enough to warrant her complaint!
We’re with you, Shifra!
Developers: give “Export to PDF” its own menu item, damnit! And ensure that this pipeline preserves all application-level semantics as Tagged PDF!
PDFacademicBot for March 2026
The PDFacademicBot brings academic research on PDF and related technologies to the industry’s attention.
Ali Andra Prasetyo Siregar et al. (March 2026) “Utilization of AI-Based Microsoft Edge PDF Reader as a Support Medium for Digital Literacy and Research for Arabic Education Students,” Journal of Arabic Language, 6(1), p. 17. https://journal.iaimnumetrolampung.ac.id/index.php/mantiqutayr/article/download/7433/2655.
Ayodeji, S., Ehinmilorin, E. and Aigbe, F. (2026) Detection of Malicious PDF Attachments with TabTransformer: A Scalable, Feature-Efficient Approach for Phishing Defense. Preprint. https://doi.org/10.5281/zenodo.18676482.
Cernușca, L. (2026) “Single Tax Return for the Period 2025–2026. The Transition from Smart PDF to Web Form,” CECCAR Business Review, 7(1), pp. 25–34. https://ideas.repec.org//a/ahd/journl/v7y2026i1p25-34.html.
Hilmi, M.A.A., Khare, N. and Iglesias, N. (March 2026) A Reliability Evaluation of Hybrid Deterministic-LLM Based Approaches for Academic Course Registration PDF Information Extraction. Available at: https://doi.org/10.13140/RG.2.2.36191.32164.
Inamdar, Z. et al. (2025) “An NLP - Based Customized and Optimized Offline PDF Summarizer Using Multi - Threading Approach,” 2025 IEEE Pune Section International Conference (PuneCon). 2025 IEEE Pune Section International Conference (PuneCon). https://doi.org/10.1109/PuneCon67554.2025.11378812.
J. Briskilal, Kapaganti Pardha Sai, and Maadhu Karthik Reddy (April 2026) “Multilingual PDF Translation using IndicTrans2,” Intelligent and Sustainable Systems: AI, Green IoT, and Adaptive Automation in Electrical and Communication Technologies. 2025 ed. CRC Press (International Conference Proceedings in Pathway of Electrical, Automation, Communication, and Electronics (PEACE-2025)). https://books.google.com.au/books?id=WBfFEQAAQBAJ&newbks=0&printsec=frontcover&pg=PT482&dq=PDF&hl=en&redir_esc=y#v=onepage&q=PDF&f=false.
Kehinde Ajayi (Dec. 2025) SCITEUQ: TOWARD UNCERTAINTY-AWARE COMPLEX SCIENTIFIC TABLE DATA EXTRACTION AND UNDERSTANDING. PhD, Computer Science. Old Dominion University, USA. at: https://digitalcommons.odu.edu/cgi/viewcontent.cgi?article=1194&context=computerscience_etds.
Gao, L. and Yan, Z. (2026) “AdvDetector: PDF Adversarial Sample Detection Based on Path Entropy and Perturbation Sensitivity,” IEEE Transactions on Consumer Electronics. https://doi.org/10.1109/TCE.2026.3665251.
Matczuk, M. and Traczyński, M. (March 2026) “Geometry-aware fragile watermarking with cryptographic functions for authenticity verification of glTF 3D models,” Advances in Science and Technology. Research Journal [Preprint]. https://www.astrj.com/Geometry-aware-fragile-watermarking-with-cryptographic-functions-for-authenticity,218894,0,1.html.
Nasir, A. (March 2026) An Interpretable Multi-Layer Scanner for Detecting Text Obfuscation Indicators in PDF Documents. https://www.researchgate.net/publication/401886957_An_Interpretable_Multi-Layer_Scanner_for_Detecting_Text_Obfuscation_Indicators_in_PDF_Documents.
Priyanka More et al. (2026) “PDF query tool using LLMs: Enhancing document interaction and analysis,” Information and Communication Systems, pp. 252–256.https://doi.org/10.1201/9781003650201-42.
Shanmukha, S., Saleef, S. and Sukumar, C. (2026) “Literature Survey on Multilingual OCR-Based PDF Search System,” INTERNATIONAL JOURNAL OF ENGINEERING DEVELOPMENT AND RESEARCH, 14(1), pp. 857–861. https://rjwave.org/ijedr/viewpaperforall.php?paper=IJEDR2601235.
Shiralaskar, H. et al. (Jan. 2026) “AARVIK: A Web-Based PDF Question Answering System Using Vector Embeddings and Large Language Models,” 2026 7th International Conference on Mobile Computing and Sustainable Informatics (ICMCSI), pp. 1828–1835. https://doi.org/10.1109/ICMCSI67283.2026.11412871.
Thornton, K. et al. (2025) “Human Verification of LLM-Powered Structured Data Extraction from Image Files,” Joint Ontology Workshops (JOWO) - Episode XI: The Sicilian Summer under the Etna. 15th International Conference on Formal Ontology in Information Systems (FOIS 2025), CEUR Workshop. https://ceur-ws.org/Vol-4176/ifow-3.pdf.
Yesugade, K. et al. (Dec. 2025) “AI-Based Text Extraction from Images and PDF Documents,” 2025 IEEE Pune Section International Conference (PuneCon). 2025 IEEE Pune Section International Conference (PuneCon), pp. 1–6. https://doi.org/10.1109/PuneCon67554.2025.11378389.
