


Chrome-plated PDFs: Exploring Google Chrome’s new PDF capabilities
Member NewsDecember 11, 2020

Member NewsDecember 11, 2020
About iText
The views expressed in this article are those of the author(s) and do not reflect the policies or positions of the PDF Association.
Tagged PDF output
As of Chrome version 85, printing a webpage and choosing the "Save as PDF" destination will automatically generate a tagged PDF that contains extra metadata about the document’s structure, including elements such as headings, lists, tables, paragraphs, and image descriptions. This metadata is crucial for accessibility software such as screen readers used by blind and visually impaired users, and tagged PDFs are much more accessible to users with such disabilities.
As noted by Dominic Mazzoni, technical lead for Chrome accessibility:
“We think adding this metadata to PDFs is a perfect fit for Chrome, because that information is already available in well-structured, accessible web pages. We hope this helps make more content exported from Chrome to be accessible to even more users.”
Many organizations that publish content online for public consumption require that all PDF must be accessible, whether as a matter of policy or, to comply with the requirements of local laws such as Section 508 of the U.S. Rehabilitation Act. We’ve written about the Section 508 requirements for PDFs before, noting it specifies PDFs must meet the PDF/UA standard to be compliant. While it’s not explicitly stated that a tagged PDF produced by Chrome will meet the PDF/UA requirements, it should be understood that this will depend on the metadata present in the source webpage, and that a well-structured tagged PDF goes a long way towards achieving PDF/UA compliance.
In addition, Google has worked closely with CommonLook, a well-established player in the PDF accessibility space, and like iText, a member of the PDF Association which actively participates in setting PDF standards. While discussing this work with the PDF Association, Ferass Elrayes, CommonLook's Co-CEO and Director of Development, and a key participant in the development of PDF/UA since 2004, said:
“CommonLook provided technical and standards-related advice to the Google team working on the project. There are obvious challenges and still more to be done as the quality of the tagging is highly dependent on the underlying HTML. But clearly this is a major step forward and we continue to work with Google to provide guidance as they progressively improve the tagging."
Yet tagged PDFs are not just useful for making PDFs more accessible to people with disabilities. PDFs containing metadata that accurately describes the content also makes it easier for software that needs to automatically process and extract data from PDFs.
As Dominic Mazzoni points out:
"This change will benefit end-users directly when they want to generate an accessible PDF, but also indirectly, as content creators who use an HTML-based workflow to produce PDFs now have another option to use that generates tagged PDFs."
Tagged PDF and ngPDF
Tagged PDFs are also a prerequisite for ngPDF (or next-generation PDF), for which a derivation algorithm was published by the PDF Association last year. The ngPDF concept is to produce responsive HTML content from a PDF document, using its tags to accurately represent the content of the source PDF. If you’re not familiar with this technology, we recommend taking a look at the ngPDF site, which contains a demonstration application developed by Dual Lab showing how the algorithm derives a responsive, yet accurate HTML presentation of the PDF’s content, which can then be consumed on a variety of devices with no need for a PDF viewer.
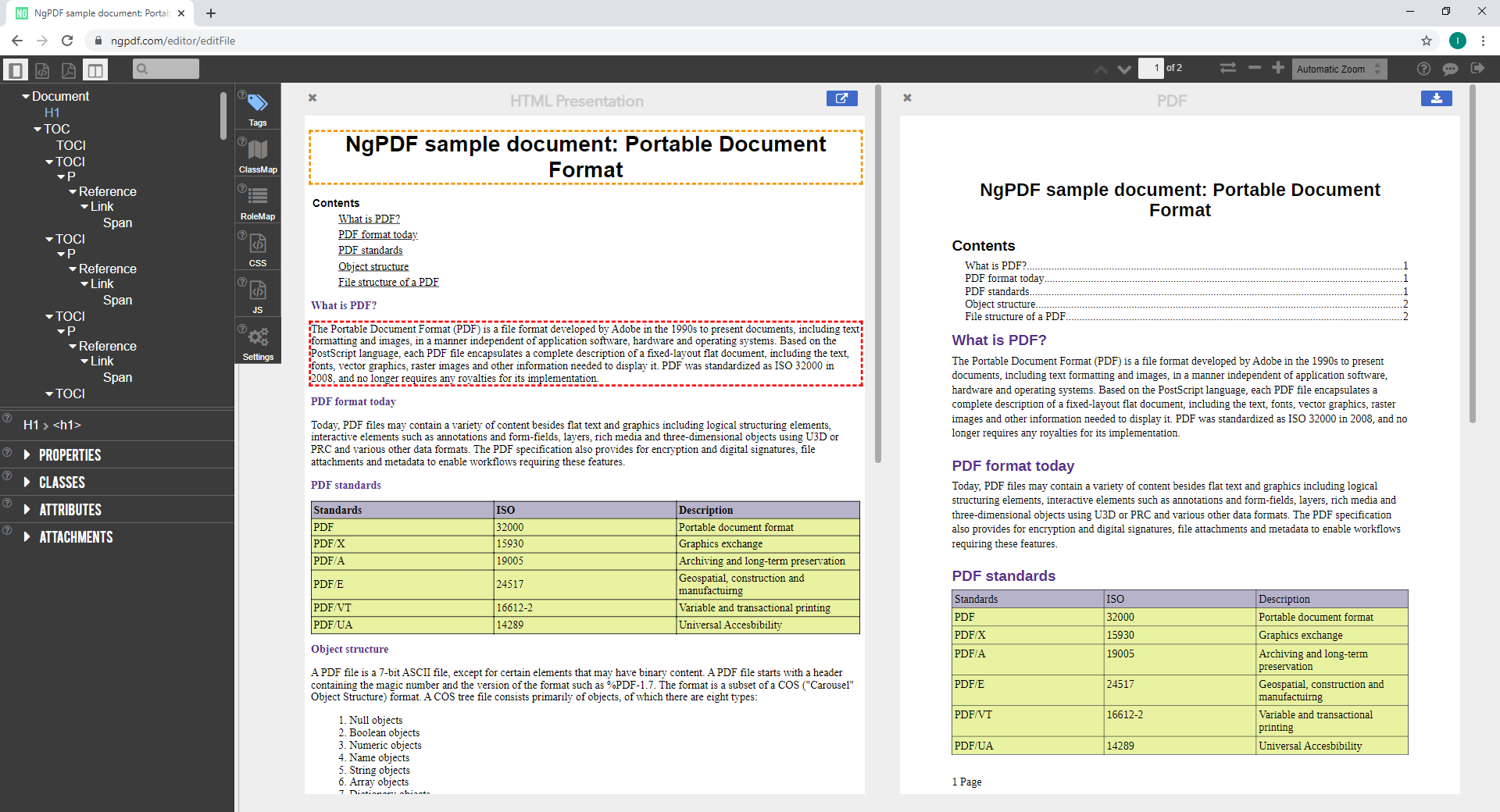
Viewing the HTML representation of the example PDF document in the ngPDF demonstration application
You might also notice that the demonstration application was developed using iText’s PDF technology. We’ll soon be presenting a white paper going into more detail about how the derivation algorithm works, along with iText code samples for parsing the structure tree and performing text extraction. Don’t miss it!
PDF form filling and saving
Exciting as the tagged PDF output for webpages are though, we knew this feature was coming for a while. What was a surprise was that Chrome 85 also introduces the possibility of filling out and saving PDF forms directly from the browser, meaning you can even close the form, then reopen it to carry on from where you left off. With so much business now happening completely online due to coronavirus, this is sure to be appreciated by people needing to fill out application forms, insurance claims, or complete Passenger Locator forms for travel purposes.
Where next for Chrome and PDF?
Google does note that they still have work to do to improve the quality of tagged PDFs, and also improving Chrome’s built-in PDF reader to better consume tagged PDFs.
Perhaps they may utilize some kind of machine learning to aid with things such as language and image recognition, or even more complex tasks like determining the correct reading order, as discussed in the talk presented by our own André Lemos at last year’s NDC Sydney conference?
We’ll be following these developments with interest.
Still have questions?
If you are interested in learning more or have additional questions, contact us
If you are interested in learning more about the iText 7 suite, click here
Original post: https://itextpdf.com/en/blog/itext-news-technical-notes/chrome-plated-pdfs-exploring-google-chromes-new-pdf-capabilities
The iText Suite is a comprehensive PDF SDK which includes iText Core and optional add-ons to give you the flexibility to fit your needs. iText Core is an open source PDF library that you can build into your own applications and is a re-imagining of the popular iText 5 engine…
Read more