


When you need a PDF
PDF in the WildJune 23, 2026

PDF in the WildJune 23, 2026
About PDF Association staff
 Porcelain PDF
Porcelain PDF
We’re loving the porcelain PDFs on display at the Basel Social Club in Switzerland to represent “the office”! According to the artist, Alan Belcher, only 10 were made.
Much as we appreciate such commemorations of our favorite format, we tend to prefer vendor-neutral representations. Clearly, Alan lives within the MacOS ecosystem!
That’s one way to burn AI tokens!
“A 50-page PDF can cost you 75,000 to 150,000 tokens before Claude has read a word of it. On a 200,000-token context window, that is most of your working space gone on one document. The reason is not the text, it is due to the way that Claude ingests a PDF.”
So says developer David Such.
Don’t dumb it down to pixels
One sledgehammer approach to cybersecurity is to reduce files to pixels (images). Yes, this disarms malicious files, but does nothing to address the much larger (for documents) problem of phishing attacks, fraudulent documents, and other disinformation.
https://dangerzone.rocks/ openly admits to rendering many document formats, including PDF and Microsoft Word, to pixels and then re-wrapping them into a PDF. The result? Low-quality, inaccessible documents, content that cannot be reused, dead forms, rich media, and 3D. A far better approach is to ensure that all applications are up-to-date, have the appropriate permissions correctly configured, block scripting, or that simple, viewing-only applications are used.
Big Tech adds support for accessible math according to PDF 2.0
On June 2, Microsoft announced a degree of support for ISO-standardized accessible math in PDF files.
Likewise, in its June 2026 release, Adobe shipped updated support in Acrobat for assistive technology access to MathML.
“Dynamic” content isn’t always your friend
This travel app vendor makes a case against PDF for travel itineraries. And fair enough – a PDF of your itinerary from 3 months ago won’t include a last-minute change by the airline.
Does that mean that travel companies should no longer send their clients PDFs?
The answer depends on the assumption that travelers will always have a live internet connection with sufficient bandwidth to obtain the latest information. Of course, that assumption also underlies the business model of this commentator.
An internet connection, however, is not guaranteed when on a flight, a ship, a train, etc. You might only be able to refer to a PDF after all. Fixed PDFs can also provide travelers with evidence against last-minute downgrades.
Meanwhile, another engineer completely understands “Why PDF Remains the Standard for Business Documents in 2026”.

ZUGFeRD 2.5 and Factur-X 1.09 update and corrigendum
On June 10 a corrective update for ZUGFeRD and Factur-X, the popular e-invoicing systems which support PDF 2.0 and PDF/A-4, was posted; here are the English and German versions.
On 11 June, they published a corrigendum also as v2.5.
The corrections affect the Schematron for the EXTENDED profile.
A new “AI-native” document format?
A group of companies has announced DocLang, which they set against PDF as “... a machine-readable document standard your models can actually trust.”
This is not a novel idea. Various Markdown-based pipelines, JSON-based schemas, XML formats, and other projects (Unstructured.io, Apache Tika) have claimed this space for years (if not decades).
DocLang sets out as yet another format to express the output of machine-based document understanding, but coherent and correct document understanding itself is the hard problem. If diverse systems extract different semantic structures from the same content, a common XML container doesn’t resolve that disagreement.
In the case of Tagged PDF, DocLang merely re-expresses what the PDF already formally defines.
New online ICC color profile validation utility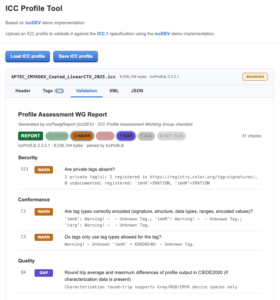
A free browser-hosted ICC validation and check utility built on top of the open-source WASM iccDEV technology was demonstrated at the recent ICC meetings, allowing users to easily check, validate, and easily comprehend ICC color profiles.
For example, this link opens a sample ICC to the Profile Assessment report tab.
veraPDF 1.30.2 release and security policy
The latest release of veraPDF introduces some fixes and a new security policy.
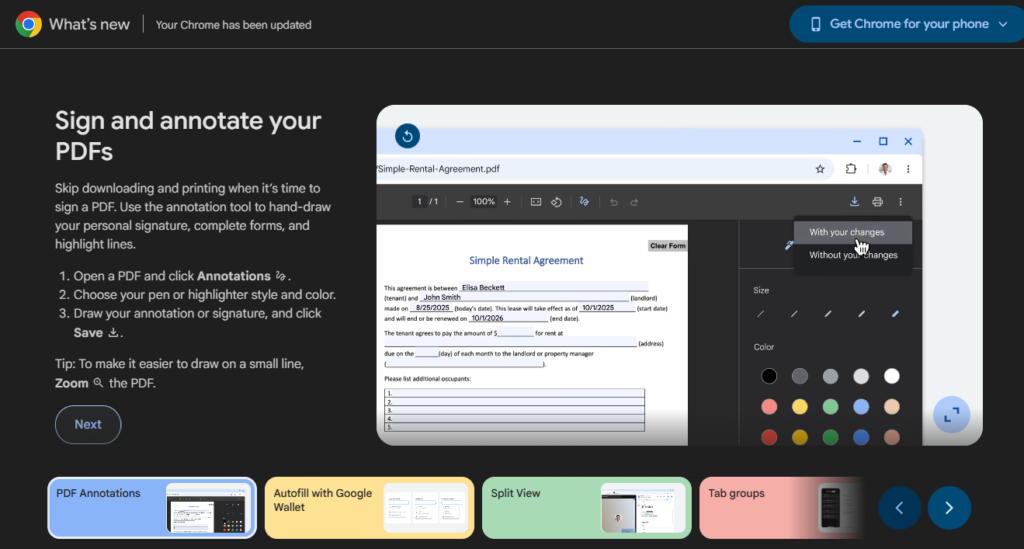
Google Chrome update continues to promote PDF
The Google Chrome version 149.0.7827.54 post-install promotion page headlines with PDF capabilities. As we’ve previously mentioned, Google’s “signing” feature does not provide cryptographic digital signatures, but merely handwritten scribbles.
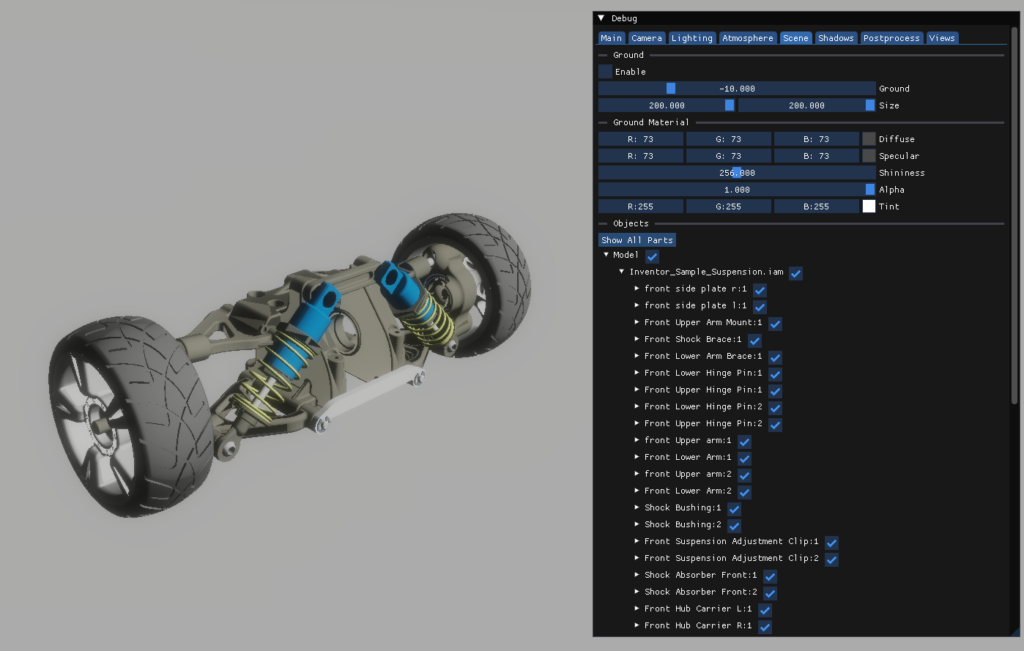
Open source nanoPRC library supports 3D PDF
A new open-source PRC library called nanoPRC is now available. With four different 3D formats supported in PDF (U3D (defined by ECMA-363 3rd edition), PRC (defined by ISO 14739-1), STEP AP 242 (in PDF 2.0 via ISO TS 24064:2023), and glTF (in PDF 2.0 via ISO 32007:2024)), we hope this means that more open-source PDF viewers will now move to adopt 3D PDF.
PDFacademicBot for June 2026
The PDFacademicBot brings academic research on PDF and related technologies to the industry’s attention.
Anvitha, B. (May 2026) Evasion-Resistant PDF Malware Detection Using Statistical Byte-Level Features. Master of Science thesis. University of Dayton. https://ecommons.udayton.edu/graduate_theses/7666.
Ashaf Uddaula et al. (2025) “An Ensemble Machine Learning Framework for Malicious PDF Detection Using Static and Structural Features | Atlantis Press,” Proceedings of the International Conference on Intelligent Data Analysis and Applications (IDAA 2025). International Conference on Intelligent Data Analysis and Applications (IDAA 2025), Atlantis Press, p. 13. https://doi.org/10.2991/978-94-6239-664-7_62.
Birhanu, K.M. et al. (April 2026) From PDF to Knowledge Node: A Dual-Prompting LLM Framework for Bibliographic Metadata Extraction in Thyroid Research Documents. https://www.researchgate.net/publication/403799050_From_PDF_to_Knowledge_Node_A_Dual-Prompting_LLM_Framework_for_Bibliographic_Metadata_Extraction_in_Thyroid_Research_Documents
Ciesiółka, M. et al. (May 2026) “ForMaT: Dataset for Visually-Grounded Multilingual PDF Translation.” arXiv. https://doi.org/10.48550/arXiv.2605.15794.
Md Didarul Islam (May 2026) ARTIFICIAL INTELLIGENCE LEARNING SUPPORT APPLICATION FOR DOCUMENT-GROUNDED STUDY: Using Retrieval-Augmented Generation with PDF and Slide Documents. Degree Programme in Information Technology. Oulu University of Applied Sciences. https://www.theseus.fi/bitstream/handle/10024/927720/Islam_Md-Didarul.pdf?sequence=2.
Grinchenko, M. and Kutsenko, D. (May 2026) “COMPARATIVE STUDY OF TRANSFORMER-BASED AND INTELLIGENT DOCUMENT ANALYSIS METHODS FOR AUTOMATED EXTRACTION OF MEDICAL DATA FROM PDF DOCUMENTS,” Bulletin of National Technical University “KhPI”. Series: System Analysis, Control and Information Technologies, (1 (15)), pp. 85–90. https://doi.org/10.20998/2079-0023.2026.01.14.
Gupta, K. (May 2026) SRIJAN TF-PDF Framework: A Governance-First Architecture for Enterprise Document Transformation and Preservation. Available at: https://doi.org/10.13140/RG.2.2.35802.09928.
Krishna, G. et al. (April 2026) “Machine Learning-Based Detection of Malicious PDF Files: A Comparative Analysis,” pp. 65–73. https://doi.org/10.1007/978-3-032-18349-1_7.
Li, X. et al. (May 2026) “CREST: Chemical Reaction Extraction from Scientific Texts.” Research Square. https://doi.org/10.21203/rs.3.rs-9230400/v1.
Liu, S. and Ming, J. (2026) “Semantic Integrity Failures in Document-to-LLM Supply Chains.” arXiv. Available at: https://doi.org/10.48550/arXiv.2606.15020.
Prem Kumar K et al. (May 2026) “RAG Based Chatbot for PDF Question Answering: An Intelligent Document Interaction System Using Retrieval-Augmented Generation,” International Journal of Emerging Trends in Computer Science and Information Technology, 7(2), pp. 246–253. https://doi.org/10.63282/3050-9246.IJETCSIT-V7I2P131.
Reddy, P.V. et al. (May 2026) “PDF Knowledge Extraction System with RAG and CAG Models,” 2026 7th International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), pp. 745–751. https://doi.org/10.1109/ICICV68925.2026.11554726.
Soric, M. et al. (Aug. 2026) “Benchmarking Table Extraction from Heterogeneous Scientific PDF Documents,” Proceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining. KDD’26, USA: ACM SIGKDD, p. 11. https://pierre.senellart.com/publications/soric2026benchmarking.pdf.
Stefan Genchev, Nina Schwanke, and Georg Carle (May 2026) “Confidential, Web-based PDF Signing Approvals for Remote Signing Solutions,” Open Identity Summit 2026. Open Identity Summit 2026, Germany: German Computer Science Society (Gesellschaft für Informatik), Fraunhofer Institute for Industrial Engineering IAO and the Hochschule für Technik und Wirtschaft Dresden, pp. 19–34. https://doi.org/10.18420/OID2026_02.
Rahul J Teradal et al. (April 2026) “A Retrieval-Augmented Conversational Framework for Reliable Question Answering on PDF Documents,” Computer Engineering and Applications, 16(4), pp. 119–124. https://journalcea.com/wp-content/uploads/9-Apr-2026.pdf
Ravikiran, S., Sri Raghunadh Kakani, and Yang Xu (2026) “Efficiency in Action: Automating Bookmarking for CRFs and Other Regulatory,” PharmaSUG 2026, p. 11. https://pharmasug.org/proceedings/2026/SS/PharmaSUG-2026-SS-243.pdf
Zheng, H. (June 2026) “A Private Web-Based Pipeline for Converting Images and PDF Pages into Editable PowerPoint Shapes,” Journal of Computer Science and Frontier Technologies, 3(3), p. 28. https://doi.org/10.63313/JCSFT.9084.
Zhao, K., Balaji, B. and Lee, S. (June 2026) “Extracting Product Carbon Footprint in PDF Documents using Question Answering Framework,” Proceedings of the 17th ACM International Conference on Future and Sustainable Energy Systems. New York, NY, USA: Association for Computing Machinery (E-Energy ’26), pp. 584–596. https://doi.org/10.1145/3744255.3798128.
Zhu, W., Mazeen Mujthaba, M. and Wong, K. (June 2026) “Reversible data hiding in PDF files by overlapping characters,” J. Inf. Secur. Appl., 97(C). Available at: https://doi.org/10.1016/j.jisa.2026.104375.
