

UPDF introduces a new page for solopreneurs, highlighting AI-powered PDF editing, OCR, e-signatures, and cross-platform document workflows for one-person businesses.

UPDF introduces a new page for solopreneurs, highlighting AI-powered PDF editing, OCR, e-signatures, and cross-platform document workflows for one-person businesses.

The mailroom has evolved from conveyor belts to intelligent workflows. Solimar Systems unifies print and digital communications, secures sensitive documents, enables personalized output, and makes archived files instantly retrievable with SOLsearcher.
axes4 has achieved ISO/IEC 27001 certification, demonstrating our commitment to protecting sensitive information through internationally recognized information security standards and secure document workflows.
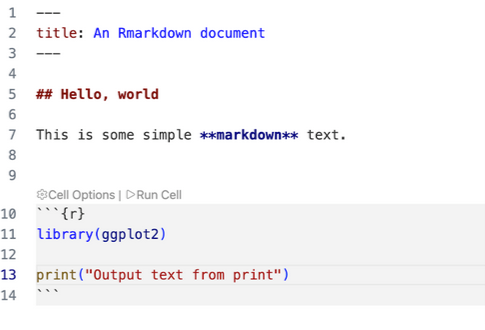
Discover how R users can incorporate PDF accessibility checks into reproducible reporting workflows for more accessible documents.

We’re pleased to introduce our Topic Rooms, the new home for discussions across PDF Association working groups.
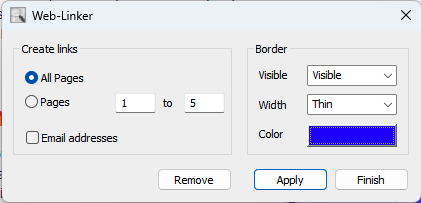
The latest Auto-Link release for Adobe Acrobat automatically detects and creates web and email links – even when URLs span multiple lines. A single click is all it takes to enrich large PDF publications, manuals and catalogs with fully functional hyperlinks.

The pdfRest API Toolkit Container Image BYOL is now available on AWS Marketplace, bringing enterprise-grade PDF processing directly to Amazon ECS and Amazon EKS environments. This containerized solution allows organizations to maintain total data sovereignty within their own private cloud while running over 40 REST API endpoints.

iText Suite 9.7 brings native WebP image support to iText Core, a reworked layout engine enabling dynamic page margins and automatic footnotes, and Sinhala, Tibetan, and S’gaw Karen script support for pdfCalligraph. There’s also new CSS selector support and grid layout fixes in pdfHTML, improvements to pdfOCR, and hardened security.

Learn how PDF standards have evolved from basic document sharing to supporting accessibility, compliance, security, and long-term preservation. Explore PDF versions, compliance standards, and the latest developments shaping digital documents.

Datalogics updates Adobe PDF Library 21 with .NET and Java support, Vietnamese OCR, updated NuGet/Maven packages, and SDK enhancements.