


EAA gets PDF/UA
PDF in the WildMay 18, 2026

PDF in the WildMay 18, 2026
About PDF Association staff
EAA gets PDF/UA
The upcoming revision to the European Accessibility Act (EN 3401 549 v 4.1.0) includes references to PDF/UA-1 and PDF/UA-2! As PDF (and PDF accessibility!) people, however, we are obliged to note that although this ETSI PDF is tagged, it is not tagged correctly, and it does not conform to PDF/UA.

ISO TC 42 publishes HDR standard
ISO TC 42 Photography has recently published ISO 22028-5:2026 Photography and graphic technology - Extended colour encodings for digital image storage, manipulation and interchange - Part 5: High dynamic range and wide colour gamut encoding for still images (HDR/WCG). This document was previously published in 2023 as an ISO Technical Specification (TS), but is now a full International Standard (IS).
The PDF Association maintains an official liaison with ISO TC 42, enabling members to review and comment on all their draft documents.
Google’s Gemini now creates PDFs, but …
… after much prompting Gemini’s PDF generator sadly proves incapable of producing Tagged PDF, leaving accessibility on its to-do list.

PDF displacing printer drivers
 A recent blog post discusses major changes in the Microsoft Windows print space. Here, we highlight some key points … from our perspective:
A recent blog post discusses major changes in the Microsoft Windows print space. Here, we highlight some key points … from our perspective:
Printing is going through a major shift, driven by Microsoft’s move toward driverless printing. What sounds like a platform change is actually a deeper architectural one. It changes where rendering happens and what gets sent to printers.
Windows is moving to an IPP-based model, aligned with Mopria and IPP Everywhere, with third-party drivers expected to be phased out around 2027. Instead of device-specific languages, printing is now built around a small set of standard formats.
Those formats are PDF, PCLm and PWG Raster. In practice, systems try PDF first for quality and efficiency, fall back to PCLm for simpler devices, and finally use PWG as a guaranteed baseline. That flow defines modern printing.
This is where PCLm becomes interesting. Despite the name, it is not PCL in the traditional sense. Classic PCL is a command language where the printer renders the page. PCLm does the opposite. The page is rendered in advance, converted to a raster image, typically JPEG, and wrapped inside a very simple PDF structure. The printer is no longer interpreting instructions, it is just decoding and printing an image.
The name comes from continuity rather than technical accuracy. It replaces PCL in many workflows and signals an efficient, device-friendly format. In reality, it is much closer to a constrained PDF than to any traditional Printer Command Language.
We note that PCLm is a proprietary format developed by HP with a related US patent, whereas PDF/R-1 is an ISO standard (ISO 23504-1:2020, formerly a PDF Association and TWAIN industry specification known as PDF/raster). The IEEE Printer Working Group 5102.3-2004 PDF/is (image streamable) format from 2004 pre-dates both these as simplified PDF formats based around image data.
Bottom line: PDF is successfully displacing the dreaded proprietary Microsoft Windows printer drivers, matching the capabilities that CUPS (Common Unix Printing System) brought to Linux years ago, and later adopted by Apple.
“Pretty Darn Fascinating” – Tedium’s history of PDF
A couple of years ago Tedium, which covers “strange and unusual descriptions of common things, explained in extreme depth”, updated its history of the PDF format, which editor Ernie Smith considers “Pretty Darn Fascinating”. As an outsider’s take on our beloved format, it’s pretty good.
The PDF Association’s forthcoming movie on the history of PDF (see the “Beyond Camelot” trailer) will shed more light on this piece of history!

PDF forensics – lots to talk about!
We encourage developers, document examiners, fraud investigators, and cybersecurity analysts interested in PDF forensics to join the PDF Forensics LWG!
Tamper detection …
Lurii has three recent posts about tamper detection in PDF on Medium. He’s made many good points here, but some are a bit simplistic.
LLMs for PDF forensics? What could go wrong?
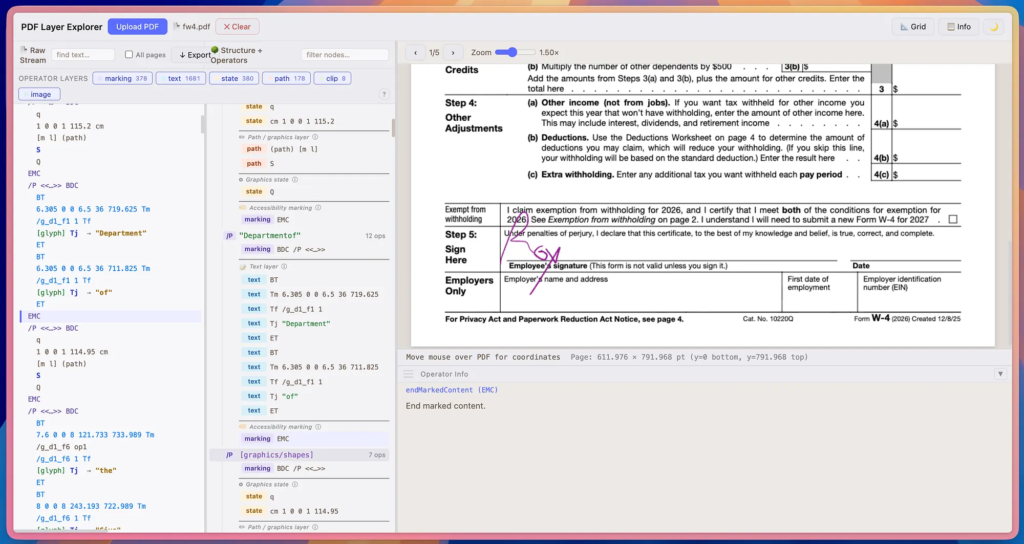
Ingrid Stevens offers an interesting take on how AI systems come to (try to) understand PDF. Thanks to a web-based GUI PDF forensics tool, “PDF Layer Examiner” (a single HTML file utilizing pdf.js), she uncovers a few of the (many) pitfalls that both human and LLM-led forensics examination will encounter. It’s an especially interesting read for PDF developers who are curious about how the format is perceived by those who are new to the format.
Epstein PDFs: just because a tool says “0 pages” doesn’t make it so!
Writing on Substack, Rye Howard-Stone reports on content he found in the Epstein files that the US Department of Justice’s PDF analysis tools simply skipped.
In so doing, he’s revealed that the government’s approach to forensic imaging is not what it could or should be, as some of the “files” he found contain recoverable content.
He says:
“No other public reporting has identified this data. It was invisible to every bulk processing pipeline because every bulk processing pipeline skips files that report zero pages.”
“None of these five files are corrupted in the traditional sense. They are forensic imaging artifacts — fragments of hard drives that were captured during evidence collection and packaged with .pdf extensions because that’s what the DOJ’s processing pipeline expected.”
Yeah, that could be a problem!
Compute your PDFs wisely, or it will cost you!
This developer has noticed the difference between trying to process PDFs as PDFs vs. dumbing them down to images, in his case, 90%+ of PDF tokens. A concrete data point supporting our recent FAQ on AI and PDF!
From the “PDF in culture” desk

PDFacademicBot for May 2026
The PDFacademicBot brings academic research on PDF and related technologies to the industry’s attention.
Ali, N. et al. (May 2026) “Toward an NLP Toolkit for Extracting Requirements from Standards,” 2026 IEEE International Systems Conference (SysCon). 2026 IEEE International Systems Conference (SysCon), pp. 1–8. https://doi.org/10.1109/SysCon66367.2026.11503554.
Anvitha Battineni (May 2026) EVASION-RESISTANT PDF MALWARE DETECTION USING STATISTICAL BYTE-LEVEL FEATURES. Master of Computer Science. University of Dayton. https://etd.ohiolink.edu/acprod/odb_etd/ws/send_file/send?accession=dayton177818800239644&disposition=inline.
Gao, L., Yan, Z. and Gelenbe, E. (May 2026) “RobCert: Certifying robustness of malicious PDF detection against structure-aware evasion attacks,” Information Sciences, 752, p. 123600. https://doi.org/10.1016/j.ins.2026.123600.
Haghighian Roudsari, A., Habibi Lashkari, A. and Loh, W.-K. (May 2026) “Unveiling malicious PDF behavior: Interpretable classification and profiling malicious PDF using TabNet,” Journal of Information Security and Applications, 100, p. 104487. https://doi.org/10.1016/j.jisa.2026.104487.
Kermode, L. and Crichton, W. (April 2026) “Document Infrastructure for Augmented Reading,” Science and Technology for Augmenting Reading (STAR). CHI 2026 Workshop, Barcelona, Spain, p. 4. https://chi-star-workshop.github.io/src/assets/pdf/papers/DocumentInfrastructureForAugmentedReading%20-%20Will%20Crichton.pdf.
Kirtz, J.L. (May 2026) “Save As…: The PDF as archive, authentic interface and epistemic object,” Media, Culture & Society, p. 01634437261442008. Available at: https://doi.org/10.1177/01634437261442008.
Kotrike, S.C. and Sinha, G. (April 2026) “PDF Malware Detection: Explainable Machine Learning Modelling PDF Malware Detection,” AIJFR - Advanced International Journal for Research, 7(2). https://doi.org/10.63363/aijfr.2026.v07i02.4215.
Liu, M. et al. (April 2026) “Lightweight and Production-Ready PDF Visual Element Parsing.” arXiv. https://doi.org/10.48550/arXiv.2604.23276.
Keah Tandon (April 2026) “Automating Literature Synthesis: Parsing and Structuring PDF Highlights (poster).” SAAS Student Success Assessment, April. https://scholarcommons.sc.edu/cgi/viewcontent.cgi?article=1007&context=aiday2026.
Rakshitha, B.J. et al. (March 2026) “DocMind: Conversational PDF QA with RAG,” 2026 1st International Electronics & Packaging Technologies Conference: Bridging Skills & Innovation for India’s Industry (EPT India), pp. 1–6. https://doi.org/10.1109/EPDMC67535.2026.11496558.
Rajan Upadhyay (March 2026) Document-Grounded Question Answering via Retrieval-Augmented Generation: Design, Implementation, and Evaluation of an End-to-End RAG-Based PDF Intelligence System. https://www.researchgate.net/publication/404468475_Document-Grounded_Question_Answering_via_Retrieval-Augmented_Generation_Design_Implementation_and_Evaluation_of_an_End-to-End_RAG-Based_PDF_Intelligence_System
Yang, Q. et al. (May 2026) “BabelDOC: Better Layout-Preserving PDF Translation via Intermediate Representation.” arXiv. https://doi.org/10.48550/arXiv.2605.10845.
