


A case study in PDF forensics: The Epstein PDFs
This article details a PDF forensics case study on a small, random selection of the Epstein PDF files released by the US Department of Justice (DoJ). The tranche contains 4,085 PDF files, with an estimated 5,879 remaining unreleased. Key findings include:
- A difference in PDF version reporting between forensic tools.
- The presence of two incremental updates.
- The discovery of a hidden (orphaned) document information dictionary revealing the software used in processing.
- The DoJ avoided JPEG images to prevent metadata leakage.
- Overall, the DoJ’s sanitization workflow could be improved to reduce file size and information leakage.

A case study in PDF forensics: The Epstein PDFs
This article details a PDF forensics case study on a small, random selection of the Epstein PDF files released by the US Department of Justice (DoJ). The tranche contains 4,085 PDF files, with an estimated 5,879 remaining unreleased. Key findings include:
- A difference in PDF version reporting between forensic tools.
- The presence of two incremental updates.
- The discovery of a hidden (orphaned) document information dictionary revealing the software used in processing.
- The DoJ avoided JPEG images to prevent metadata leakage.
- Overall, the DoJ’s sanitization workflow could be improved to reduce file size and information leakage.
Marketing Working Group – E-Invoicing: Is PDF’s Dominance in Jeopardy?
To encourage marketing staff to sign up for the PDF Technology Marketing Working Group we decided to record a recent presentation to the MWG by one of our members, and … Read more







August 2023 by Peter Wyatt

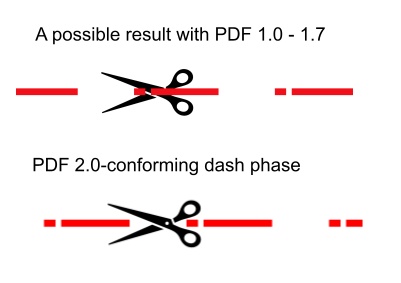
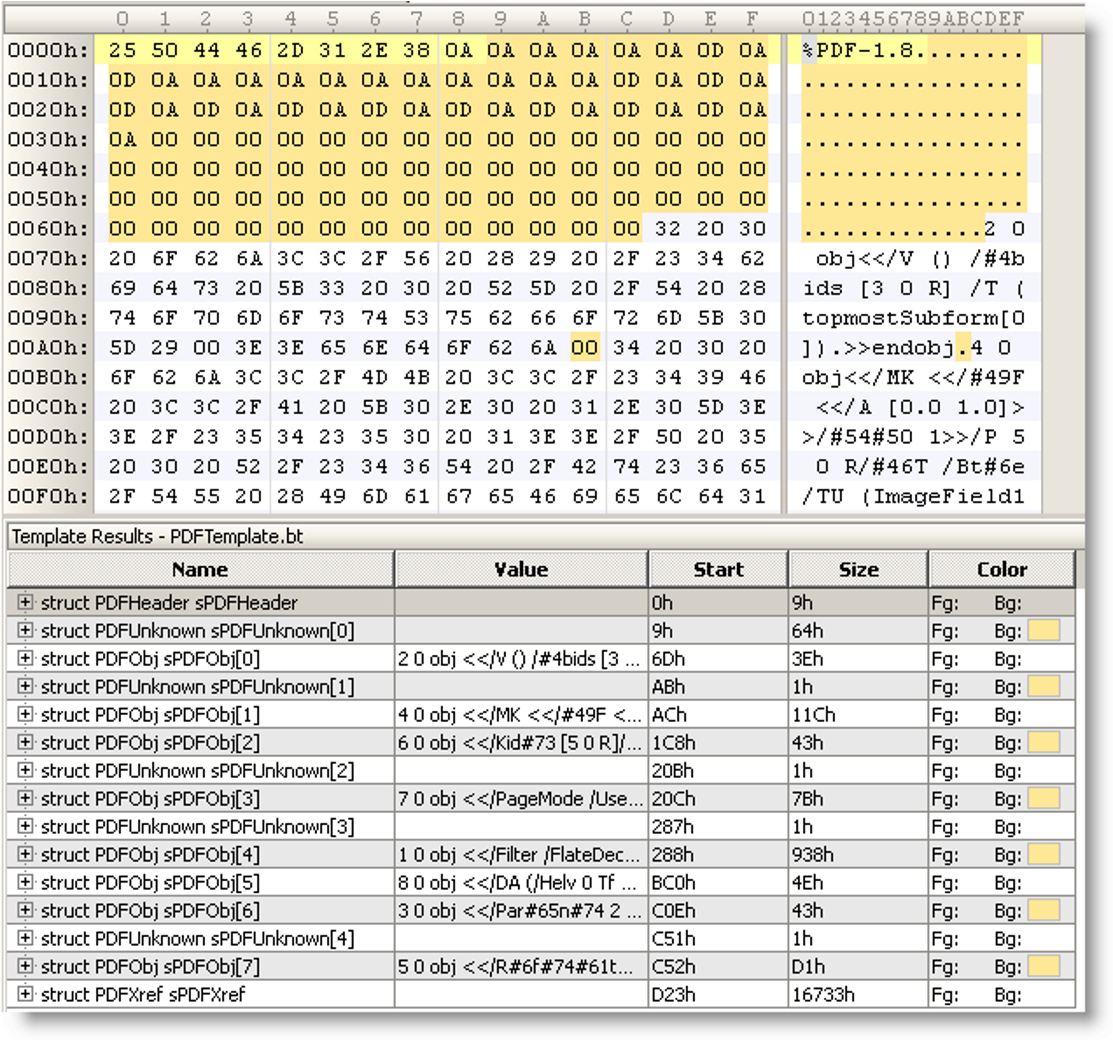
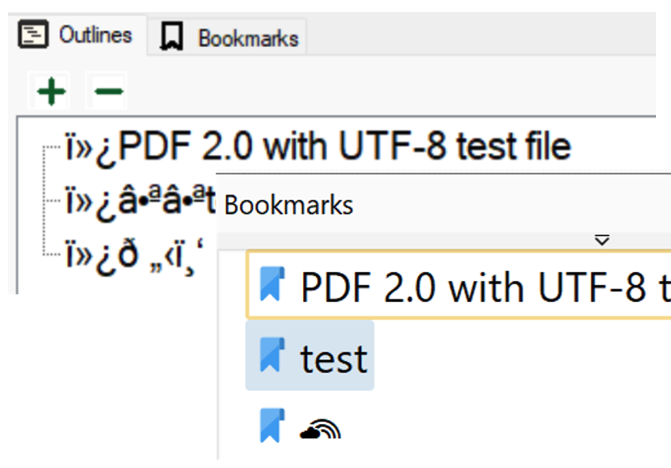
PDF is a large, complex specification! Developers often look for first steps in its implementation. This article offers some suggestions.

July 2023 by Duff Johnson

Overcoming ossification requires everyone to agree on the strategy and specific technical changes affecting all stakeholders.




