


PDF is trending on GitHub
PDF in the WildApril 27, 2026
PDF in the WildApril 27, 2026
About PDF Association staff
PDF Week London 2026 is almost here!
The next round of face-to-face PDF Association and ISO meetings at PDF Week London is almost here! Be sure to register with us online, and if you’ll be attending ISO meetings, please register on the ISO site as well. PDF Association members not attending in person can join their Working Group meetings online as usual.
We look forward to many productive meetings and opportunities for information conversation! And beer.
If you can’t make London, please consider joining us in South Korea in mid-October.
veraPDF 1.30 released
On April 22, the Open Preservation Foundation announced the latest version of veraPDF, 1.30. Read the detailed release notes on GitHub.
PDF is trending on GitHub
We’ve written about how “PDF” appears in macro-scale trend indicators such as Google Trends. A GitHub trend analyzer demonstrates that interest in “PDF” has exploded over the last 18 or so months.
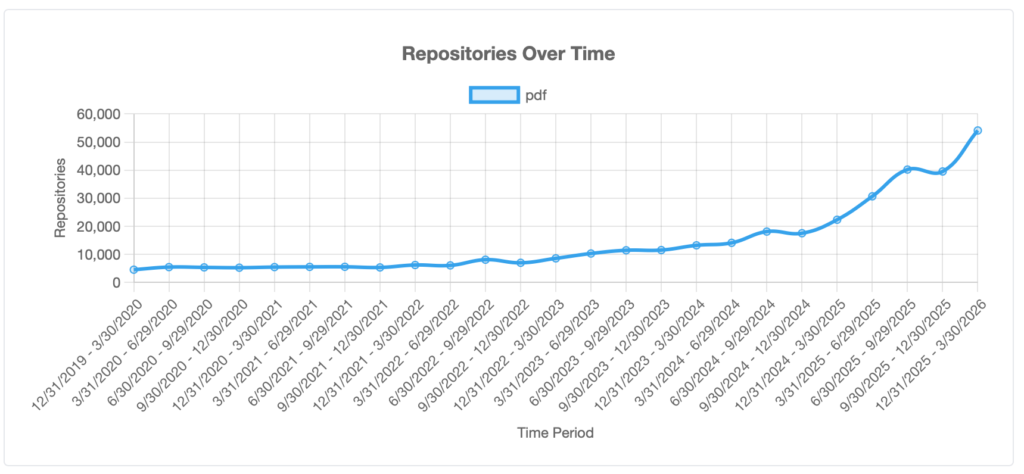
The surge in interest coincides with the emergence of AI, which may drive much of the recent activity. Whatever the reason, GitHub statistics prove that PDF’s technical ecosystem is vibrant and growing.
PDF/UA-1 gets its first errata correction
The PDF Association’s PDF/UA Technical Working Group has published its first industry correction against ISO 14289-1:2014 (PDF/UA-1) to assist all implementers with a common technical understanding. Thanks to our generous sponsors, ISO 14289-1:2014 (PDF/UA-1) is also available as a no-cost download.
Will PDF become even more important?
Forbes reports that Google has been granted Patent US12536233B1, “AI-generated content page tailored to a specific user”) which describes a system that will completely replace a web page with an AI-generated version.
Even though one might imagine many valuable uses for such capabilities, his patent has serious implications for meaningful web archiving and presents a challenge to establishing “documents of record” on the web.
PDF doesn’t have this issue. Authors who publish information as a PDF are assured of a trusted appearance, just as intended. Another advantage of standalone persistent files: users who depend on referencing specific PDFs could record cryptographic hashes in case Google goes beyond web content and decides to apply AI to re-author PDFs!
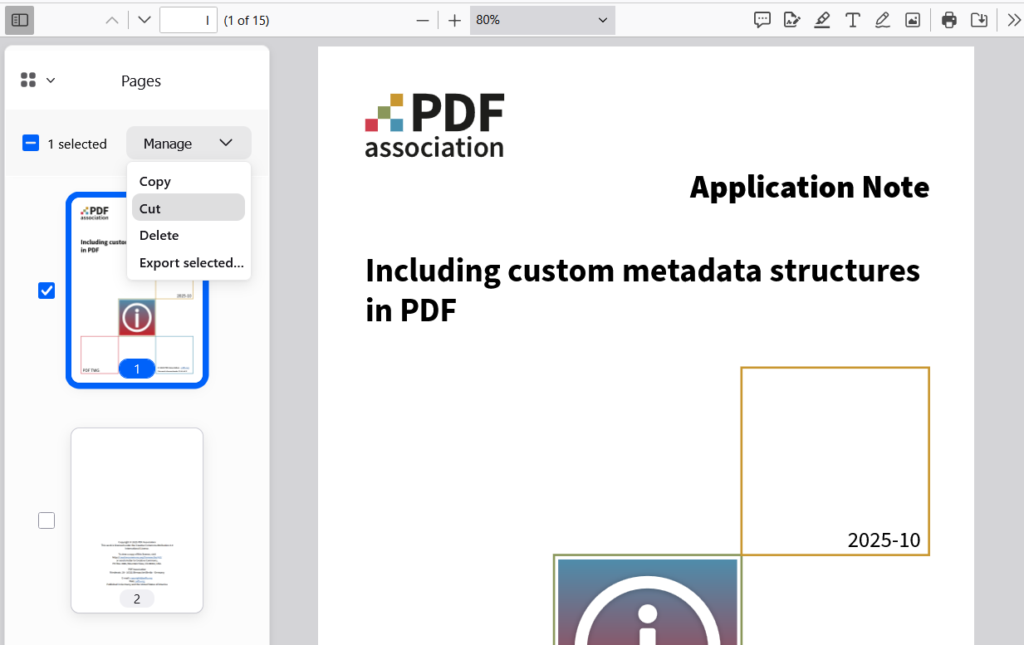
Firefox v150 extends PDF editing capabilities
The latest v150 update of Mozilla’s Firefox browser adds new PDF editing capabilities, allowing users to manipulate pages in PDF files.
The new features include duplicating (copying) pages, deleting pages, and exporting selected pages for web or local PDFs.
This feature is so new that it hasn’t even made it to the main Firefox PDF editor page yet!
iPRES 2026 “digital pantry” seeks new ingredients
As part of the iPRES 2026 Tools Demo Session: The Digital Preservation Bake Off, the iPRES organizing committee is looking to expand its digital Bake-Off Pantry of tools and sample data.
The committee is seeking contributions to help challenge and inspire the development of new preservation tools. As PDF/A (ISO 19005) plays a significant role in modern digital preservation efforts and continues to evolve, the PDF community is sure to have something to offer.
To submit, please fill out this form with Pantry submissions closing on Friday, September 4th.
Mustang Project releases 2.23.0 “Bonne Journées de la Facture Électronique”
The Mustang Project is an open-source, Java-based GitHub project supporting ZUGFeRD/Factur-X electronic invoices, which leverage PDF/A.
The project recently announced v2.23.0 in readiness for the FNFE-organized JFE event, a free online event on May 7, 2026, regarding France’s September deadline for B2B invoicing.
We are saddened to note that the ticket to implement PDF 2.0 and PDF/A-4 support remains open.
For those looking for example e-invoice PDFs, look no further than ZUGFeRD’s corpus repository.
New JSON definitions for PDF extensions
Our latest public GitHub repository provides simple JSON definitions for well-known PDF extensions. This data is used on our https://pdfa.org/extensions page and can be used by developers to present consistent information to users. This new public repository parallels our JSON definitions for PDF Declarations and the PDF Declarations webpage.
If you’re a developer with your own registered prefix and documented extension or declaration, please file a new issue in the appropriate repository to be added to our resources.
Accessibility: it’s all about the authoring
This recent article offers nugatory claims and bad advice based on outdated information, but nonetheless highlights a real problem: far too many PDF files are inaccessible.
We‘ve said it before, and we‘ll say it again: inaccessible content is not just a PDF problem; it’s caused by authors who fail, for whatever reason, to provide the necessary information or take due care when exporting content.
Semantics in both HTML and PDF originate from the same place – an authoring tool. For any given piece of content, both HTML and PDF can be equally accessible or inaccessible, depending on the author's actions and decisions. Content without any semantic headings, lists, and other markup gets exported to HTML as "<P> soup" and "P tag soup" in PDF. Authors who apply heading and list styles correctly will see the corresponding semantics in both HTML and Tagged PDF output.
Modern office suites increasingly include integrated accessibility checkers supported by AI, ensuring authors are aware of accessibility issues in their content before exporting. The most popular browsers directly export an accessible PDF that matches HTML‘s accessibility.
The question for publishers, content managers, and policy-makers isn’t “PDF or accessible web content”, it‘s “When is fixed-layout, paginated, device-independent, and persistent representation required?”
PDFacademicBot for April 2026
The PDFacademicBot brings academic research on PDF and related technologies to the industry’s attention.
Sushant Aggarwal (April 2026) Interactive Knowledge Extraction: A Human-in-the-Loop Approach for PDF Structuring and Knowledge Graph Integration. Thesis, Master of Science in Computer Science. Gottfried Wilhelm Leibniz Universität. https://repo.uni-hannover.de/server/api/core/bitstreams/75bfa8ab-44c2-40b9-a290-aae23f22b2d7/content.
Baah, E.K. et al. (Feb. 2026) “An Interpretable Hybrid Model for PDF Malware Detection Using CNN and Vision Transformer,” 2026 28th International Conference on Advanced Communications Technology (ICACT). pp. 1–10. https://doi.org/10.23919/ICACT68090.2026.11431538.
Bachyr, O.E. et al. (April 2026) “Empirical Evaluation of PDF Parsing and Chunking for Financial Question Answering with RAG.” Available at: https://doi.org/10.1145/3786583.3786911.
Campos De Souza, P.V., Batista, H.R. and Silva, A.M.D. (March 2026) “SBBrasil TrainSheets: From PDF Records to Dental View Classification With a Human-in-the-Loop Imaging Pipeline,” IEEE Access, 14, pp. 49428–49444. https://doi.org/10.1109/ACCESS.2026.3675860.
Guilherme Marques dos Santos, J. et al. (April 2026) “From PDF to RAG-Ready: Evaluating Document Conversion Frameworks for Domain-Specific Question Answering.” arXiv. https://doi.org/10.48550/arXiv.2604.04948.
Han, F. et al. (2026) “LaTeX2Layout: High-Fidelity, Scalable Document Layout Annotation Pipeline for Layout Detection.” Fortieth AAAI Conference on Artificial Intelligence (AAAI-26), p. 9. https://ojs.aaai.org/index.php/AAAI/article/download/40349/44310.
Holloway, C. et al. (March 2026) “Accessibility metadata: A journey to understanding and implementation,” Information Services and Use, 2026(0), p. 13. https://doi.org/10.1177/18758789261435328.
Horn, P. and Keuper, J. (March 2026) “Benchmarking PDF Parsers on Table Extraction with LLM-based Semantic Evaluation.” arXiv. https://doi.org/10.48550/arXiv.2603.18652.
Iorio, A.D. et al. (2026) “A Tool for Extracting Citation Graphs From Scholarly PDF Articles,” IEEE Access, 14, pp. 48277–48297. https://doi.org/10.1109/ACCESS.2026.3677777.
Jaykumar Patel et al. (March 2026) “AUTOMATED EDUCATIONAL ASSESSMENT THROUGH QUESTION GENERATION FROM PDF RESOURCES,” International Journal For Research In Advanced Computer Science And Engineering, 12(1), pp. 8–13. https://ijracse.org/index.php/cse/article/download/2476/1386
Kim, S. et al. (March 2026) “CPR: Corrupted PDF recovery algorithm for digital forensic investigations,” Forensic Science International: Digital Investigation, 56, p. 302054. https://doi.org/10.1016/j.fsidi.2026.302054.
Kotrike, S.C. and Sinha, G. (2026) “Pdf Malware Detection: Explainable Machine Learning Modelling Pdf Malware Detection,” AIJFR - Advanced International Journal for Research, 7(2). https://doi.org/10.63363/aijfr.2026.v07i02.4215.
Lockridge, T. (April 2026) “The past and future of digital publishing,” Computers and Composition, 80, p. 103002. https://doi.org/10.1016/j.compcom.2026.103002.
Mowar, P., Steinfeld, A. and Bigham, J.P. (April 2026) “iTagPDF: Towards Finally Automating PDF Accessibility,” Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems. New York, NY, USA: Association for Computing Machinery (CHI ’26), pp. 1–17. https://doi.org/10.1145/3772318.3790289.
Mulugu, K. (April 2026) DocuQuery: Design, Implementation, and Empirical Analysis of a Hybrid Lexical–Dense Retrieval System with LangGraph Orchestration for PDF Question Answering. Available at: https://doi.org/10.13140/RG.2.2.21211.73766.
Myasoedov, V.A. and Vishnevskaya, J.A. (2026) “Comparative Analysis of Text Extraction Methods from PDF Files for Subsequent Data Processing,” 2026 ElCon Conference of Young Researchers in Electrical Engineering, Automation & Control Systems (ElCon-EE). https://doi.org/10.1109/ElCon-EE69794.2026.11452828.
Nirumand, A., Degiovanni, R. and Cabot, J. (March 2026) “From PDF Assessments to LMS Deployment: A Model-Driven QTI-Based Framework,” p. 16. https://rdegiovanni.github.io/publications/files/RCIS2026.pdf
Park, S. et al. (2026) “REPDF: Repairing corrupted PDF files through font mapping and object relationship reconstruction,” Forensic Science International: Digital Investigation, 56, p. 302061. https://doi.org/10.1016/j.fsidi.2026.302061.
Santos, J.G.M. dos et al. (March 2026) “From PDF to RAG-Ready: Evaluating Document Conversion Frameworks for Domain-Specific Question Answering.” arXiv. https://doi.org/10.48550/arXiv.2604.04948.
Zeng, E.J. (2026) “PDF Files as Accusations: A Body Politics Perspective on Overseas Chinese Students’ Nonconsensual Sexual Experience in Self-Sharing Online Archives,” The Ambiguity of Consent. 1st ed. Routledge. https://www.taylorfrancis.com/chapters/edit/10.4324/9781003621935-15/pdf-files-accusations-edward-jiru-zeng.
