


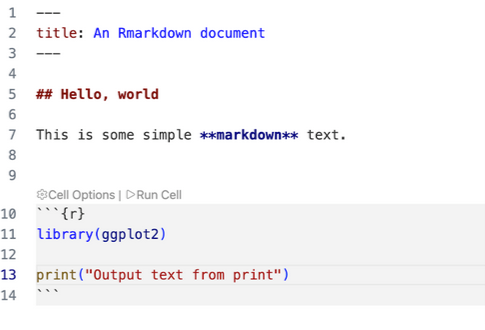
PDF 2.0 Errata Collection 3 now available
For the last 3 years the PDF Association, sponsored by Adobe, Apryse, and Foxit, has made the ISO standard that defines PDF – ISO 32000-2 – available at no cost.
The current ISO 32000-2 bundle includes PDF’s core specification and four ISO Technical Specification extensions to PDF, enabling modern cryptography and digital signature technologies in PDF 2.0. With tens of thousands of downloads since 2023, the PDF Association and its sponsors have successfully placed the latest and most up-to-date PDF specification into the hands of developers worldwide, helping improve interoperability and reduce malformed PDF files.
This edition of PDF 2.0 includes Errata Collection 3 (EC3) and is a complete replacement for the previous no-cost Errata Collection 2 (EC2) sponsored edition of ISO 32000-2:2020.
PDF 2.0 Errata Collection 3 now available
For the last 3 years the PDF Association, sponsored by Adobe, Apryse, and Foxit, has made the ISO standard that defines PDF – ISO 32000-2 – available at no cost.
The current ISO 32000-2 bundle includes PDF’s core specification and four ISO Technical Specification extensions to PDF, enabling modern cryptography and digital signature technologies in PDF 2.0. With tens of thousands of downloads since 2023, the PDF Association and its sponsors have successfully placed the latest and most up-to-date PDF specification into the hands of developers worldwide, helping improve interoperability and reduce malformed PDF files.
This edition of PDF 2.0 includes Errata Collection 3 (EC3) and is a complete replacement for the previous no-cost Errata Collection 2 (EC2) sponsored edition of ISO 32000-2:2020.

By PDF Association staff
June 2026
Featured articles
What you need to know today.




Recent articles
Informative (non-commercial) articles by PDF Association members and staff.

July 2026 by Vijayshree Vethantham (Continual Engine)

Learn how PDF standards have evolved from basic document sharing to supporting accessibility, compliance, security, and long-term preservation. Explore PDF … Read more


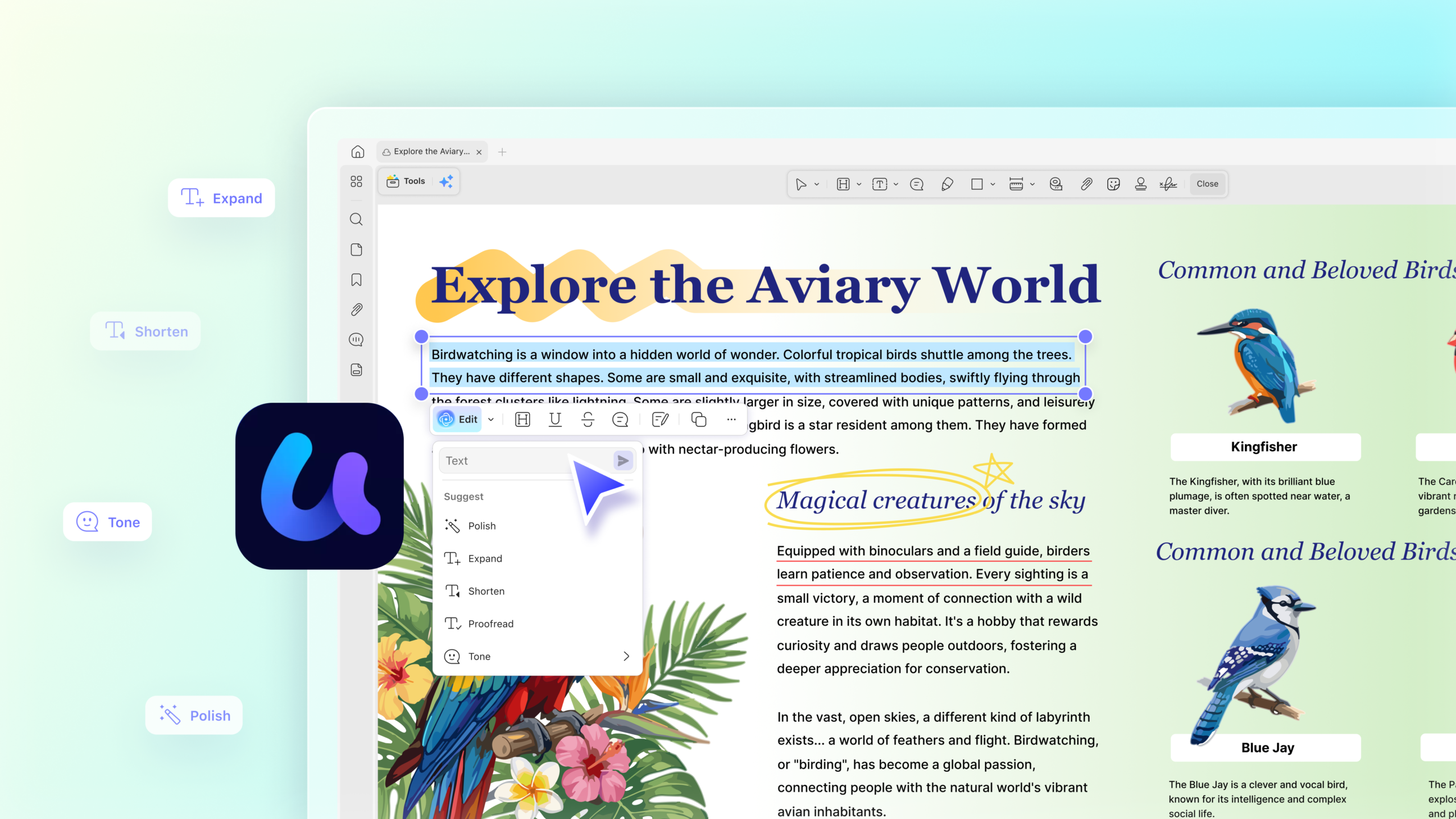
June 2026 by Vijayshree Vethantham (Continual Engine)
From untagged content and incorrect reading order to inaccessible forms and missing alternative text, PDF accessibility issues can create barriers … Read more



News from the PDF Association
Announcements, publications, events and other updates.

July 2026 by Alexandra Oettler

How can content and information be extracted from PDF documents using AI applications, such as large language models (LLMs), and … Read more


May 2026 by PDF Association staff
For those who attended PDF Week London 2026 last week, we hope that you had a great time – and … Read more

April 2026 by PDF Association staff
Developed by the LaTeX Project LWG, this guide provides critical recommendations for authors and publishers to ensure complex mathematical and … Read more

News from PDF Association members
PDF Association members post updates on their software and services.
August 2026 by axes4 GmbH
axes4 has achieved ISO/IEC 27001 certification, demonstrating our commitment to protecting sensitive information through internationally recognized information security standards and … Read more




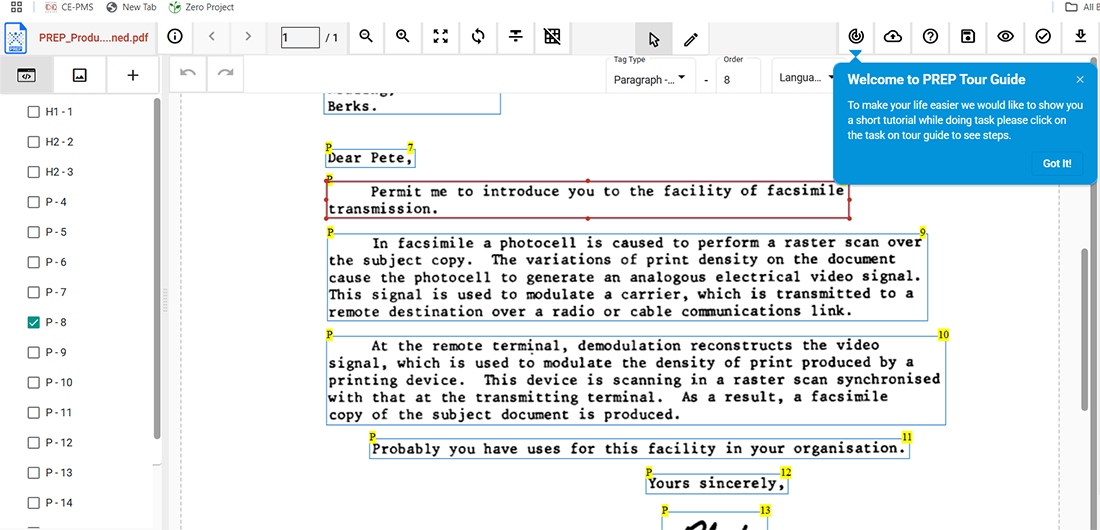
July 2026 by Lindsey Schroeder (Datalogics)

Datalogics updates Adobe PDF Library 21 with .NET and Java support, Vietnamese OCR, updated NuGet/Maven packages, and SDK enhancements.
Members‘ case studies
PDF Association members‘ case studies showcase implementations of PDF technology in daily business operations around the world.

July 2026 by Mary Ann Rowan (Solimar Systems)

Wisconsin-based ABT Mailcom transformed its mail production with the Solimar Chemistry Platform, delivered with Hansen360 and RISO. File processing dropped … Read more


June 2026 by David van Driessche (callas software GmbH)

How PDFix uses callas technology to deliver reliable PDF/UA compliance.


Members‘ white papers
PDF Association members‘ white papers inform their customers, partners and suppliers with technical or marketplace education, insights into their philosophy, solutions and technologies.


January 2022 by Jonathan Malone-McGrew (Solimar Systems)

Ryan McAbee and Pat McGrew share their thoughts on relevant Keypoint Intelligence research during this Solimar-sponsored webinar.

PDF in the Wild
Our (occasionally lighthearted) monthly post covering items of interest to PDF’s technical community.

July 2026 by PDF Association staff
PDF should not be your “tokenpocalypse” | LibreOffice comes out swinging for open formats | Android Auto brings PDF “reading” … Read more


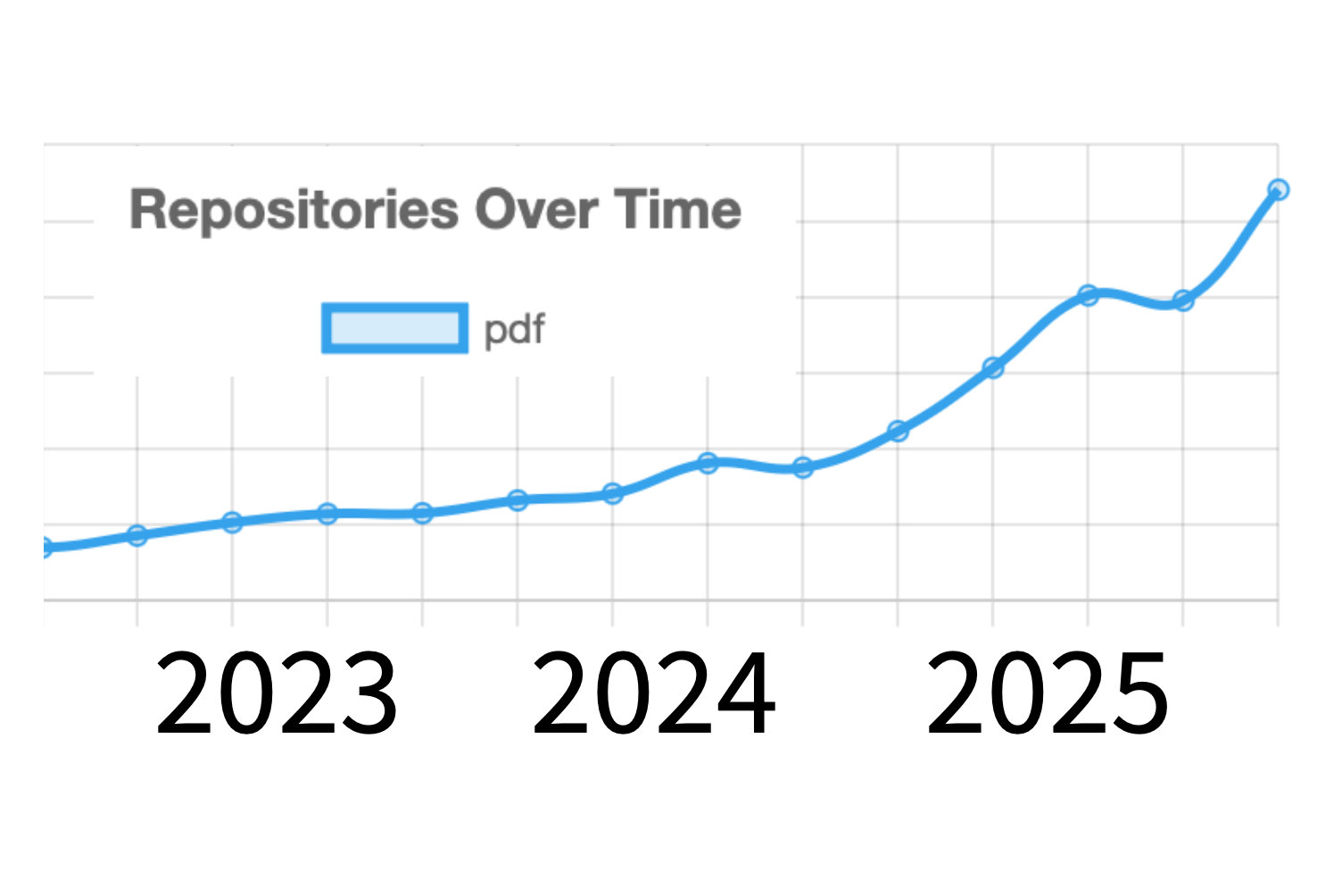
April 2026 by PDF Association staff
PDF Week London 2026 is almost here! | veraPDF 1.30 released | PDF is trending on GitHub | PDF/UA-1 gets its … Read more


PDF in the News
When PDF files feature in the news, we’ll offer our take.

December 2025 by Peter Wyatt

We report on the technical aspects of the PDF files released by the US Department of Justice in connection with … Read more



September 2019 by Duff Johnson

A poorly scanned PDF of Trump’s Ukraine call shows the risks of print-based workflows. Dirty scans, weak OCR, and missing … Read more


PDF Association news for members
Members-only content requires a login to pdfa.org.

July 2026 by PDF Association staff
We’re pleased to introduce our Topic Rooms, the new home for discussions across PDF Association working groups.

May 2026 by PDF Association staff
PDF Association members can now add contact details and social links to their profile, making author connections and networking easier.


March 2026 by PDF Association staff
Gain insights into the PDF marketplace via this exclusive report.

